
At the EA Global 2016 conference, I gave a talk on “Using Machine Learning to Address AI Risk”:
It is plausible that future artificial general intelligence systems will share many qualities in common with present-day machine learning systems. If so, how could we ensure that these systems robustly act as intended? We discuss the technical agenda for a new project at MIRI focused on this question.
A recording of my talk is now up online:
The talk serves as a quick survey (for a general audience) of the kinds of technical problems we’re working on under the “Alignment for Advanced ML Systems” research agenda. Included below is a version of the talk in blog post form. ((I also gave a version of this talk at the MIRI/FHI Colloquium on Robust and Beneficial AI.))
Talk outline:
1. Goal of this research agenda
2. Six potential problems with highly capable AI systems
2.1. Actions are hard to evaluate
2.2. Ambiguous test examples
2.3. Difficulty imitating human behavior
2.4. Difficulty specifying goals about the real world
2.5. Negative side-effects
2.6. Edge cases that still satisfy the goal3. Technical details on one problem: inductive ambiguity identification
3.1. KWIK learning
3.2. A Bayesian view of the problem
Goal of this research agenda
This talk is about a new research agenda aimed at using machine learning to make AI systems safe even at very high capability levels. I’ll begin by summarizing the goal of the research agenda, and then go into more depth on six problem classes we’re focusing on.
The goal statement for this technical agenda is that we want to know how to train a smarter-than-human AI system to perform one or more large-scale, useful tasks in the world.
Some assumptions this research agenda makes:
- Future AI systems are likely to look like more powerful versions of present-day ML systems in many ways. We may get better deep learning algorithms, for example, but we’re likely to still be relying heavily on something like deep learning. ((Alternatively, you may think that AGI won’t look like modern ML in most respects, but that the ML aspects are easier to productively study today and are unlikely to be made completely irrelevant by future developments.))
- Artificial general intelligence (AGI) is likely to be developed relatively soon (say, in the next couple of decades). ((Alternatively, you may think timelines are long, but that we should focus on scenarios with shorter timelines because they’re more urgent.))
- Building task-directed AGI is a good idea, and we can make progress today studying how to do so.
I’m not confident that all three of these assumptions are true, but I think they’re plausible enough to deserve about as much attention from the AI community as the likeliest alternative scenarios.
A task-directed AI system is a system that pursues a semi-concrete objective in the world, like “build a million houses” or “cure cancer.” For those who have read Superintelligence, task-directed AI is similar to the idea of genie AI. Although these tasks are kind of fuzzy — there’s probably a lot of work you’d need to do to clarify what it really means to build a million houses, or what counts as a good house — they’re at least somewhat concrete.
An example of an AGI system that isn’t task-directed would be one with a goal like “learn human values and do things humans would consider good upon sufficient reflection.” This is too abstract to count as a “task” in the sense we mean; it doesn’t directly cash out in things in the world.
The hope is that even though task-directed AI pursues a less ambitious objective then “learn human values and do what we’d want it to do,” it’s still sufficient to prevent global catastrophic risks. Once the immediate risks are averted, we can then work on building more ambitious AI systems under reduced time pressure.
Task-directed AI uses some (moderate) amount of human assistance to clarify the goal and to evaluate and implement its plans. A goal like “cure cancer” is vague enough that humans will have to do some work to clarify what they mean by it, though most of the intellectual labor should be coming from the AI system rather than from humans.
Ideally, task-directed AI also shouldn’t require significantly more computational resources than competing systems. You shouldn’t get an exponential slowdown from building a safe system vs. a generic system.
In order to think about this overall goal, we need some kind of model for these future systems. The general approach that I’ll take is to look at current systems and imagine that they’re more powerful. A lot of the time you can look at tasks that people do in ML and you can see that the performance improves over time. We’ll model more advanced AI systems by just supposing that systems will continue to achieve higher scores in ML tasks. We can then ask what kinds of failure modes are likely to arise as systems improve, and what we can work on today to make those failures less likely or less costly.
Six potential problems with highly capable AI systems
Problem 1: Actions are hard to evaluate
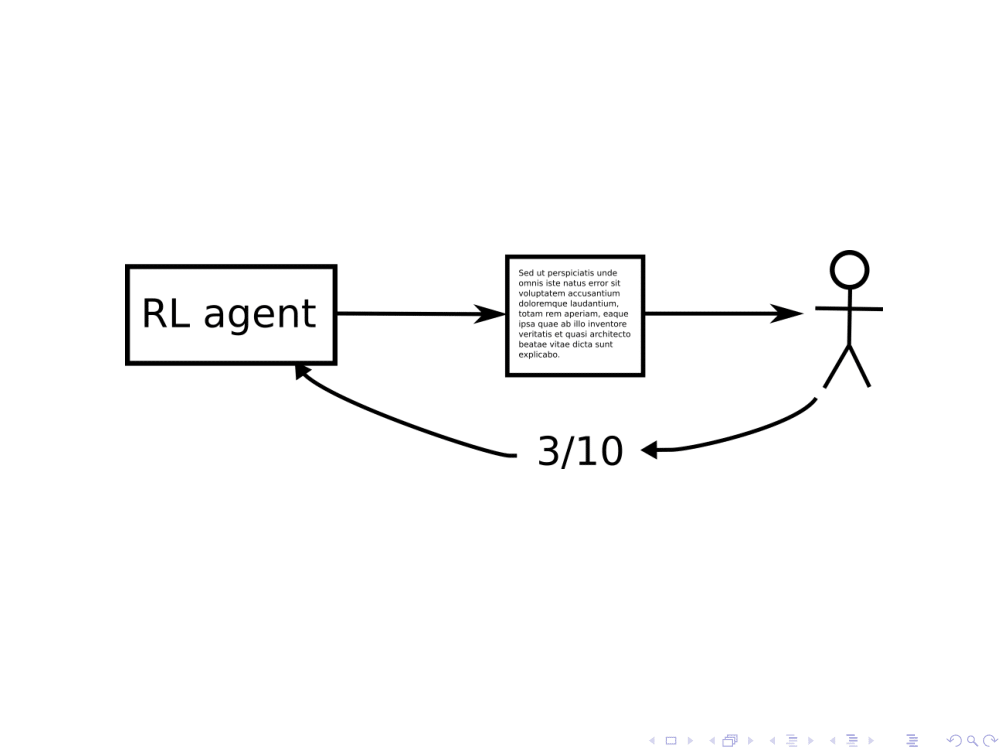 Suppose an AI system composes a story, and a human gives the system a reward based on how good the story is. ((Although I’ll use the example of stories here, in real life it could be a system generating plans for curing cancers, and humans evaluating how good the plans are.))
Suppose an AI system composes a story, and a human gives the system a reward based on how good the story is. ((Although I’ll use the example of stories here, in real life it could be a system generating plans for curing cancers, and humans evaluating how good the plans are.))
This is similar to some RL tasks: the agent wants to do something that will cause it to receive a high reward in the future. The formalism of RL would say that the objective of this RL agent is to write a story that the human is expected to give a high score to.
For this objective to actually help us receive very high-quality stories, however, we also need to know that the human understands the RL agent’s actions well enough to correctly administer rewards. This assumption seems less likely to hold for systems that are optimizing the objective much more powerfully than any present-day system. For example:
- A system much smarter than a human may be able to manipulate or coerce the human into giving a bad story a high score.
- Even if the system is less intelligent than that, it might resort to plagiarism. Plagiarism can be easier to generate than to detect, since detection often requires scouring a larger pool of source texts.
- A subhuman system might also have an advantage in inserting steganography into the story; it might take polynomial time to embed a secret message, and exponential time to detect such a message. Finding a way to discourage agents from taking covert actions like these would make it easier to monitor those actions’ effects and keep operators in the loop.
Do we have a general way of preventing this? Can we train an RL system to not only output an action (e.g., a story), but also a report that might help an overseer better evaluate the system’s performance? Following OpenAI researcher Paul Christiano, we call this the problem of informed oversight. ((See the Q&A section of the talk for questions like “Won’t the report be subject to the same concerns as the original story?”))
Problem 2: Ambiguous test examples
 Another problem: Consider a classifier trained to distinguish images of cats from images not containing cats, or trained to detect cancer. You may have lots of life experience that tells you “wild cats are cats.” If the training set only contains images of house cats and dogs, however, then it may not be possible to infer this fact during training.
Another problem: Consider a classifier trained to distinguish images of cats from images not containing cats, or trained to detect cancer. You may have lots of life experience that tells you “wild cats are cats.” If the training set only contains images of house cats and dogs, however, then it may not be possible to infer this fact during training.
An AI system that was superhumanly good at classifying images from a particular data set might not construct the same generalizations as a human, making it unreliable in new environments.
 In safety-critical settings, ideally we would like the classifier to say, “This is ambiguous,” to alert us that the image’s label is underdetermined by the labels of training set images. We could then leverage the classifier’s proficiency at classification to intervene in contexts where the system is relatively likely to misclassify things, and could also supply training data that’s tailored to the dimensions along which the original data was uninformative. Formalizing this goal is the problem of inductive ambiguity detection.
In safety-critical settings, ideally we would like the classifier to say, “This is ambiguous,” to alert us that the image’s label is underdetermined by the labels of training set images. We could then leverage the classifier’s proficiency at classification to intervene in contexts where the system is relatively likely to misclassify things, and could also supply training data that’s tailored to the dimensions along which the original data was uninformative. Formalizing this goal is the problem of inductive ambiguity detection.
Problem 3: Difficulty imitating human behavior
 One way we might want to deal with the problems of smarter-than-human AI is to just have it imitate a human. By having the system observe a human attempting to perform some task and having it learn to behave similarly, we might be able to leverage the AI system’s cognitive advantages while having it mostly stick to fairly normal strategies.
One way we might want to deal with the problems of smarter-than-human AI is to just have it imitate a human. By having the system observe a human attempting to perform some task and having it learn to behave similarly, we might be able to leverage the AI system’s cognitive advantages while having it mostly stick to fairly normal strategies.
As an example, we can consider an AI system tasked with producing the kind of picture a human would draw. How could you actually train a system on this objective?
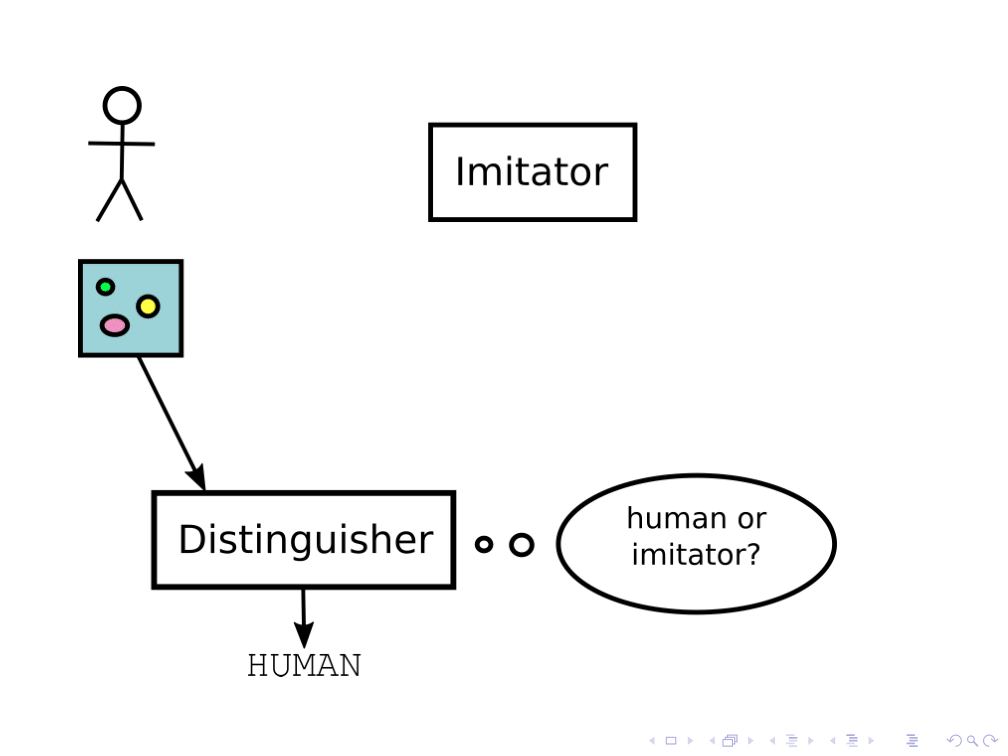
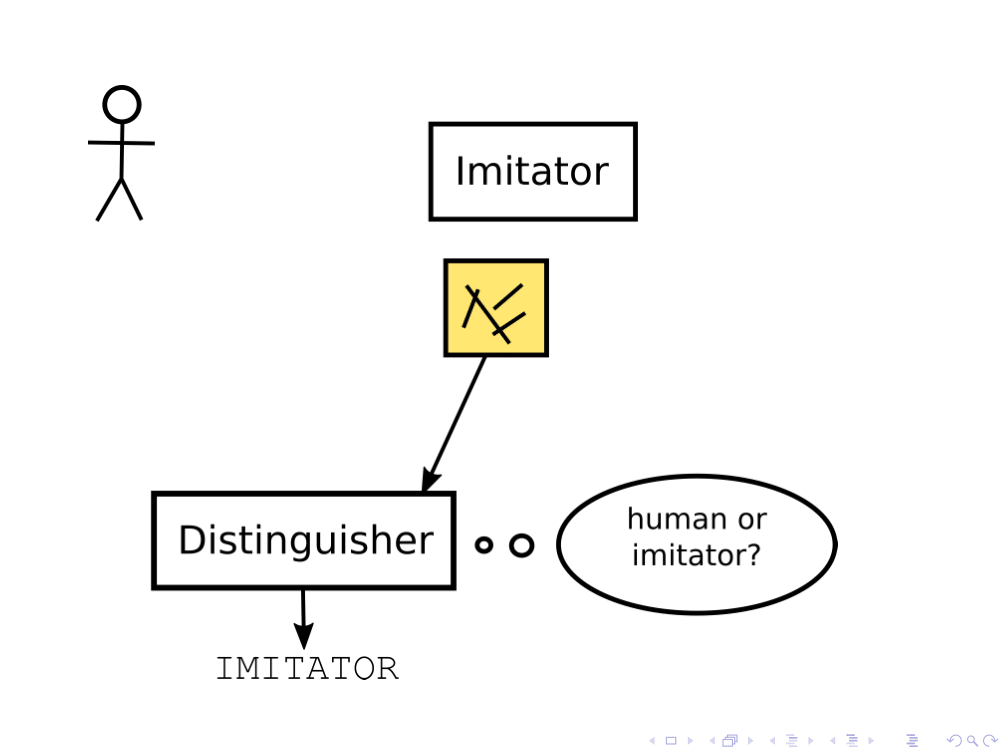 In one approach, generative adversarial networks, you have a human and two AI agents: an imitator, and a distinguisher. ((Ian J. Goodfellow et al. “Generative Adversarial Nets”. In: Advances in Neural Information Processing 27. Ed. by Z. Ghahramani et al. Curran Associates, Inc., 2014, pp. 2672-2680. URL: https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.)) The distinguisher tries to guess whether a given picture came from the human or from the imitator, and the imitator tries to produce the kinds of image that the distinguisher classifies as coming from the human.
In one approach, generative adversarial networks, you have a human and two AI agents: an imitator, and a distinguisher. ((Ian J. Goodfellow et al. “Generative Adversarial Nets”. In: Advances in Neural Information Processing 27. Ed. by Z. Ghahramani et al. Curran Associates, Inc., 2014, pp. 2672-2680. URL: https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.)) The distinguisher tries to guess whether a given picture came from the human or from the imitator, and the imitator tries to produce the kinds of image that the distinguisher classifies as coming from the human.
This is a pretty cool setup, but it raises some theoretical issues. We could ask the question, “Does the distinguisher have to be smarter than the imitator? And if so, how much smarter?” If the distinguisher is less smart than the imitator, then the imitator could covertly do very non-human-like things to the image, as long as they’re too subtle for the distinguisher to notice. An open avenue of research here is to analyze schemes like this and ask under what conditions we can get nice robustness guarantees.
For more on this problem, see Paul Christiano’s “Act-Based Agents” and “Mimicry and Meeting Halfway”.
Problem 4: Difficulty specifying goals about the real world
What if we want to train our AI system to perform a task like making a sandwich? One option might be to hook the system up to a robot in a room full of sandwich ingredients, have it perform an action sequence, and then have a human observer rate the robot’s performance based on how close it came to making a sandwich. That rating determines the robot’s reward.
We previously noted that sufficiently capable RL agents might pick actions that are hard to evaluate. Here we face the additional problem that useful tasks will often require taking physical action in the world. If the system is capable enough, then this setup gives it an incentive to take away the reward button and press it itself. This is what the formalism of RL would tell you is the best action, if we imagine AI systems that continue to be trained in the RL framework far past current capability levels.
A natural question, then, is whether we can train AI systems that just keep getting better at producing a sandwich as they improve in capabilities, without ever reaching a tipping point where they have an incentive to do something else. Can we avoid relying on proxies for the task we care about, and just train the system to value completing the task in its own right? This is the generalizable environmental goals problem.
Problem 5: Negative side-effects
Suppose we succeeded in making a system that wants to put a sandwich in the room. In choosing between plans, it will favor whichever plan has the higher probability of resulting in a sandwich. Perhaps the policy of just walking over and making a sandwich has a 99.9% chance of success; but there’s always a chance that a human could step in and shut off the robot. A policy that drives down the probability of interventions like that might push up the probability of the room ending up containing a sandwich to 99.9999%. In this way, sufficiently advanced ML systems can end up with incentives to interfere with their developers and operators even when there’s no risk of reward hacking.
This is the problem of designing task-directed systems that can become superhumanly good at achieving their task, without causing negative side-effects in the process.
One response to this problem is to try to quantify how much total impact different policies have on the world. We can then add a penalty term for actions that have a high impact, causing the system to favor low-impact strategies.
Another approach is to ask how we might design an AI system to be satisfied with a merely 99.9% chance of success — just have the system stop trying to think up superior policies once it finds one meeting that threshold. This is the problem of formalizing mild optimization.
Or one can consider advanced AI systems from the perspective of convergent instrumental strategies. No matter what the system is trying to do, it can probably benefit by having more computational resources, by having the programmers like it more, by having more money. A sandwich-making system might want money so it can buy more ingredients, whereas a story-writing system might want money so it can buy books to learn from. Many different goals imply similar instrumental strategies, a number of which are likely to introduce conflicts due to resource limitations.
One, approach, then, would be to study these instrumental strategies directly and try to find a way to design a system that doesn’t exhibit them. If we can identify common features of these strategies, and especially of the adversarial strategies, then we could try to proactively avert the incentives to pursue those strategies. This seems difficult, and is very underspecified, but there’s some initial research pointed in this direction.
Problem 6: Edge cases that still satisfy the goal
 Another problem that’s likely to become more serious as ML systems become more advanced is edge cases.
Another problem that’s likely to become more serious as ML systems become more advanced is edge cases.
Consider our ordinary concept of a sandwich. There are lots of things that technically count as sandwiches, but are unlikely to have the same practical uses a sandwich normally has for us. You could have an extremely small or extremely large sandwich, or a toxic sandwich.
For an example of this behavior in present-day systems, we can consider this image that an image classifier correctly classified as a panda (with 57% confidence). Goodfellow, Shlens, and Szegedy found that they could add a tiny vector to this image that causes the classifier to misclassify it as a gibbon with 99% confidence. ((Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. “Explaining and Harnessing Adversarial Examples”. In: (2014). arXiv: 1412.6572 [stat.ML].))
Such edge cases are likely to become more common and more hazardous as ML systems begin to search wider solution spaces than humans are likely (or even able) to consider. This is then another case where systems might become increasingly good at maximizing their score on a conventional metric, while becoming less reliable for achieving realistic goals we care about.
Conservative concepts are an initial idea for trying to address this problem, by biasing systems to avoid assigning positive classifications to examples that are near the edges of the search space. The system might then make the mistake of thinking that some perfectly good sandwiches are inadmissible, but it would not make the more risky mistake of classifying toxic or otherwise bizarre sandwiches as admissible.
Technical details on one problem: inductive ambiguity identification
I’ve outlined eight research directions for addressing six problems that seem likely to start arising (or to become more serious) as ML systems become better at optimizing their objectives — objectives that may not exactly match programmers’ intentions. The research directions were:
- Informed oversight, for making it easier to interpret and assess ML systems’ actions.
- Inductive ambiguity identification, for designing classifiers that stop and check in with overseers in circumstances where their training data was insufficiently informative.
- Robust human imitation, for recapitulating the safety-conducive features of humans in ML systems.
- Generalizable environmental goals, for preventing RL agents’ instrumental incentives to seize control of their reward signal.
- Impact measures, mild optimization, and averting instrumental incentives, for preventing negative side-effects of superhumanly effective optimization in a general-purpose way.
- Conservative concepts, for steering clear of edge cases.
These problems are discussed in more detail in “Alignment for Advanced ML Systems.” I’ll go into more technical depth on an example problem to give a better sense of what working on these problems looks like in practice.
KWIK learning
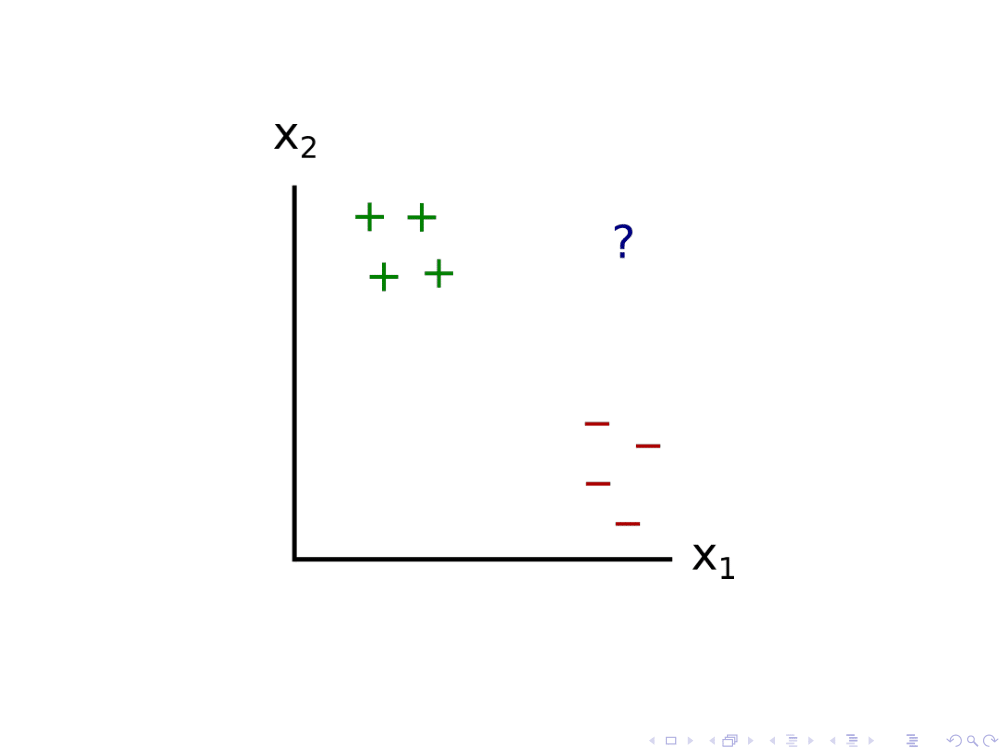 Let’s consider the inductive ambiguity identification problem, applied to a classifier for 2D points. In this case, we have 4 positive examples and 4 negative examples.
Let’s consider the inductive ambiguity identification problem, applied to a classifier for 2D points. In this case, we have 4 positive examples and 4 negative examples.
When a new point comes in, the classifier could try to label it by drawing a whole bunch of models that are consistent with the previous data. Here, I draw just 4 of them. The question mark falls on opposite sides of these different models, suggesting that all of these models are plausible given the data.
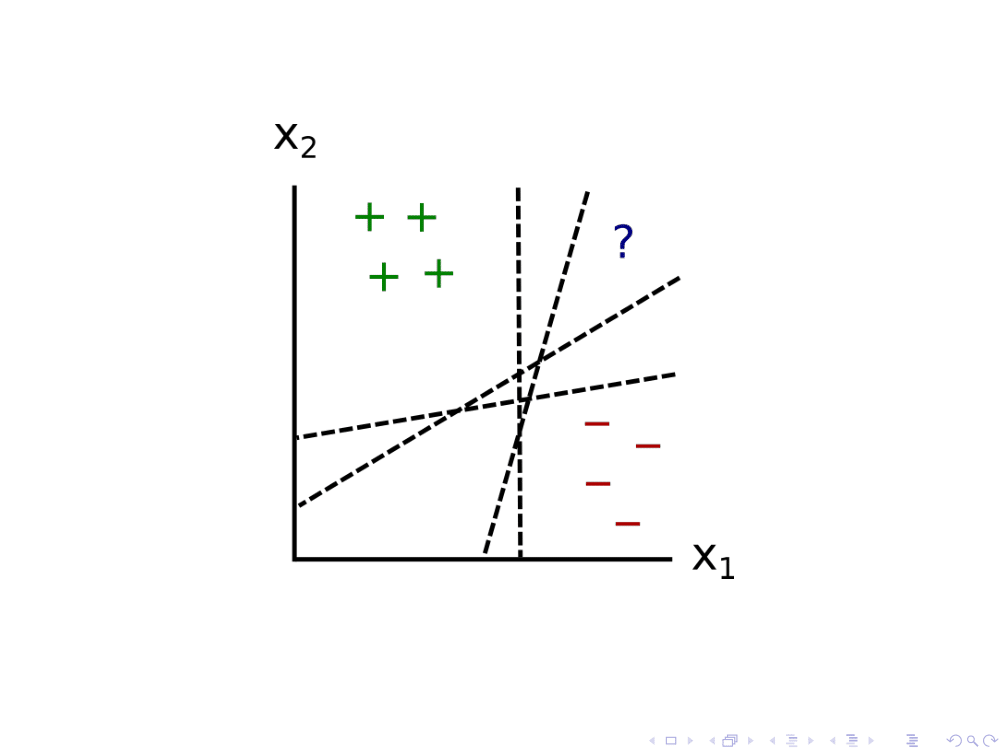 We can suppose that the system infers from this that the training data is ambiguous with respect to the new point’s classification, and asks the human to label it. The human might then label it with a plus, and the system draws new conclusions about which models are plausible.
We can suppose that the system infers from this that the training data is ambiguous with respect to the new point’s classification, and asks the human to label it. The human might then label it with a plus, and the system draws new conclusions about which models are plausible.
This approach is called “Knows What It Knows” learning, or KWIK learning. We start with some input space X ≔ ℝn and assume that there exists some true mapping from inputs to probabilities. E.g., for each image the cat classifier encounters we assume that there is a true answer in the set Y ≔ [0,1] to the question, “What is the probability that this image is a cat?” This probability corresponds to the probability that a human will label that image “1” as opposed to “0,” which we can represent as a weighted coin flip. The model maps the inputs to answers, which in this case are probabilities. ((The KWIK learning framework is much more general than this; I’m just giving one example.))
The KWIK learner is going to play a game. At the beginning of the game, some true model h* gets picked out. The true model is assumed to be in the hypothesis set H. On each iteration i some new example xi ∈ ℝn comes in. It has some true answer yi = h*(xi), but the learner is unsure about the true answer. The learner has two choices:
- Output an answer ŷi ∈ [0,1].
- If |ŷi – yi| > ε, the learner then loses the game.
- Output ⊥ to indicate that the example is ambiguous.
- The learner then gets to observe the true label zi = FlipCoin(yi) from the observation set Z ≔ {0,1}.
The goal is to not lose, and to not output ⊥ too many times. The upshot is that it’s actually possible to win this game with a high probability if the hypothesis class H is a small finite set or a low-dimensional linear class. This is pretty cool. It turns out that there are certain forms of uncertainty where we can just resolve the ambiguity.
The way this works is that on each new input, we consider multiple models h that have done well in the past, and we consider something “ambiguous” if the models disagree on h(xi) by more than ε. Then we just refine the set of models over time.
The way that a KWIK learner represents this notion of inductive ambiguity is: ambiguity is about not knowing which model is correct. There’s some set of models, many are plausible, and you’re not sure which one is the right model.
There are some problems with this. One of the main problems is KWIK learning’s realizability assumption — the assumption that the true model h* is actually in the hypothesis set H. Realistically, the actual universe won’t be in your hypothesis class, since your hypotheses need to fit in your head. Another problem is that this method only works for these very simple model classes.
A Bayesian view of the problem
That’s some existing work on inductive ambiguity identification. What’s some work we’ve been doing at MIRI related to this?
Lately, I’ve been trying to approach this problem from a Bayesian perspective. On this view, we have some kind of prior Q over mappings X → {0,1} from the input space to the label. The assumption we’ll make is that our prior is wrong in some way and there’s some unknown “true” prior P over these mappings. The goal is that even though the system only has access to Q, it should perform the classification task almost as well (in expectation over P) as if it already knew P.
It seems like this task is hard. If the real world is sampled from P, and P is different from your prior Q, there aren’t that many guarantees. To make this tractable, we can add a grain of truth assumption:
$$\forall f : Q(f) \geq \frac{1}{k} P(f) $$
This says that if P assigns a high probability to something, then so does Q. Can we get good performance in various classification tasks under this kind of assumption?
We haven’t completed this research avenue, but initial results suggest that it’s possible to do pretty well on this task while avoiding catastrophic behaviors in at least in some cases (e.g., online supervised learning). That’s somewhat promising, and this is definitely an area for future research.
How this ties in to inductive ambiguity identification: If you’re uncertain about what’s true, then there are various ways of describing what that uncertainty is about. You can try taking your beliefs and partitioning them into various possibilities. That’s in some sense an ambiguity, because you don’t know which possibility is correct. We can think of the grain of truth assumption as saying that there’s some way of splitting up your probability distribution into components such that one of the components is right. The system should do well even though it doesn’t initially know which component is right.
(For more recent work on this problem, see Paul Christiano’s “Red Teams” and “Learning with Catastrophes” and research forum results from me and Ryan Carey: “Bias-Detecting Online Learners” and “Adversarial Bandit Learning with Catastrophes.”)
Other research agendas
Let’s return to a broad view and consider other research agendas focused on long-run AI safety. The first such agenda was outlined in MIRI’s 2014 agent foundations report. ((Nate Soares and Benja Fallenstein. Agent Foundations for Aligning Machine Intelligence with Human Interests: A Technical Research Agenda. Tech. rep. 2014-8. Forthcoming 2017 in “The Technological Singularity: Managing the Journey” Jim Miller, Roman Yampolskiy, Stuart J. Armstrong, and Vic Callaghan, Eds. Berkeley, CA. Machine Intelligence Research Institute. 2014.))
The agent foundations agenda is about developing a better theoretical understanding of reasoning and decision-making. An example of a relevant gap in our current theories is ideal reasoning about mathematical statements (including statements about computer programs), in contexts where you don’t have the time or compute to do a full proof. This is the basic problem we’re responding to in “Logical Induction.” In this talk I’ve focused on problems for advanced AI systems that broadly resemble present-day ML; in contrast, the agent foundations problems are agnostic about the details of the system. They apply to ML systems, but also to other possible frameworks for good general-purpose reasoning.
Then there’s the “Concrete Problems in AI Safety” agenda. ((Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. “Concrete Problems in AI Safety”. In: (2016). arXiv: 1606.06565 [cs.AI].)) Here the idea is to study AI safety problems with a more empirical focus, specifically looking for problems that we can study using current ML methods, and perhaps can even demonstrate in current systems or in systems that might be developed in the near future.
As an example, consider the question, “How do you make an RL agent that behaves safely while it’s still exploring its environment and learning about how the environment works?” It’s a question that comes up in current systems all the time, and is relatively easy to study today, but is likely to apply to more capable systems as well.
These different agendas represent different points of view on how one might make AI systems more reliable in a way that scales with capabilities progress, and our hope is that by encouraging work on a variety of different problems from a variety of different perspectives, we’re less likely to completely miss a key consideration. At the same time, we can achieve more confidence that we’re on the right track when relatively independent approaches all arrive at similar conclusions.
I’m leading the team at MIRI that will be focusing on the “Alignment for Advanced ML Systems” agenda going forward. It seems like there’s a lot of room for more eyes on these problems, and we’re hoping to hire a number of new researchers and kick off a number of collaborations to tackle these problems. If you’re interested in these problems and have a solid background in mathematics or computer science, I definitely recommend getting in touch or reading more about these problems.