
This is part of the MIRI Single Author Series. Pieces in this series represent the beliefs and opinions of their named authors, and do not claim to speak for all of MIRI.
Before the machine learning revolution kicked AI into overdrive, I worked in reliability engineering and risk assessment at ExxonMobil. In my efforts to understand the problems posed by AI development in general and modern machine learning in particular, I sometimes find it helpful to call upon concepts from my previous field.
Reliability engineering deals with the long-term management of risk from equipment failure. It includes a mixture of statistics, incident and near miss investigation, failure analysis, probabilistic risk assessment, and long-term maintenance planning, and has been a core element of industrial manufacturing since the aftermath of World War II.
Reliability engineering is closely linked with safety engineering, and the two disciplines share a number of key concepts. In this post, I will outline a few of these concepts and discuss how they pertain to my views on artificial intelligence.
My refining and chemicals background means that many of the examples I use will be from oil and gas. Still, I aim to focus on lessons that generalize well outside this one industry. Our first topic of interest is probabilistic risk assessment, widely used in fields such as manufacturing, nuclear regulation, space flight, and national defense.
Probability, consequence, and the risk matrix
Central to the discipline of reliability engineering is the notion of quantifying and categorizing risk.
Risk has two components, probability and consequence.
Probability is the estimated likelihood of a specific outcome. When dealing with hundreds or thousands of risks, their probabilities are often rounded to within an order of magnitude for ease of comparison: 1 in 10, 1 in 100, 1 in 1000, etc.
Consequence is the badness of the specific outcome. Some consequences, such as expensive shutdowns or repairs, are measured in money1. Other consequences, such as injury or death, are simply placed into one of several qualitative buckets: for instance, injuries might be classed as one of first aid, hospitalization, long-term disability, or fatality. Even the consequences measured in money are usually given the same treatment, to make them easier to mentally categorize.
We often classify and visually organize a collection of risks using a risk matrix.
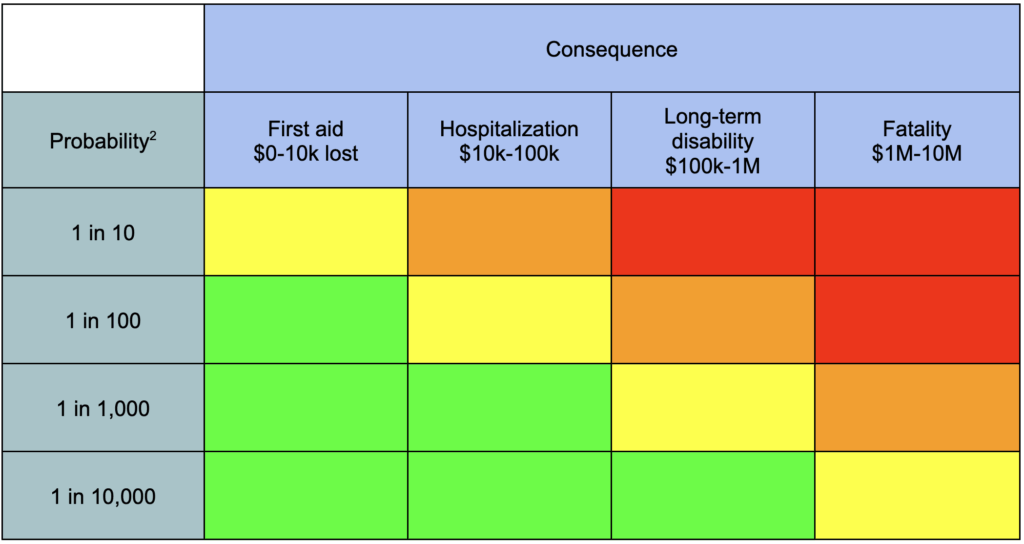
Most people who’ve worked in risk assessment will have seen some version of a risk matrix. Financial risk can also be expressed as expected losses, or the amount of money an event would cost multiplied by its estimated probability. Safety risks don’t typically get this treatment, but they do get placed into buckets, and there might be a maximum amount of money that a company is willing to spend on a given bucket of risk.
Also, if you want to do a risk assessment, you want to define a specific time interval, typically one year. Using “annualized” risk helps keep likelihood estimates bounded and consistent.
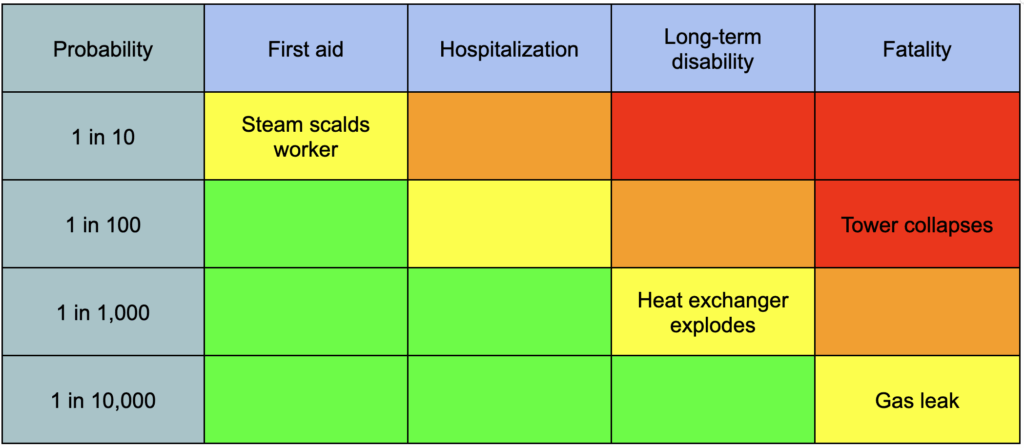
Here are some examples of safety risks that might end up on a risk matrix3:
- A valve emits steam when opened, scalding a worker (estimated at 1 in 10)
- An aging tower collapses, killing bystanders (1 in 100)
- A heat exchanger overpressures and explodes, maiming someone (1 in 1,000)
- A toxic gas leak poisons an operator (1 in 10,000)
Here’s what these look like if we put them on a risk matrix:
Figuring out how to do this more effectively, efficiently, and robustly at scale is one of the main jobs of a safety engineer or reliability engineer. For financial risks, the focus is on finding actions with high benefit-to-cost ratios; for safety risks, the focus is on mitigating especially high risks to acceptable levels.
The trillion-dollar question is: What is an acceptable level of risk?
The answer varies by industry. I’m most familiar with oil and gas, in which most competently-run US companies would consider risks in the red or orange zone above to be unacceptable. Orange-zone risks might be tolerated for a time, while mitigations are scheduled and executed, but they would be carefully monitored. Red-zone risks, if they can’t be mitigated even temporarily, might trigger a full-scale plant shutdown.4
The highest routinely-accepted single source of annual risk corresponds to (very roughly) a 1 in 10,000 chance of a single fatality. As a sanity check, this is approximately the same annual risk as the average American’s risk of dying in a car crash. To a reasonable first approximation, if you drive to work in the morning, you accept a similar level of risk to that of workers in a well-run refinery.5
These numbers are very approximate, but they do suggest a general level of risk tolerance that a first-world society is willing to accept.
Sometimes people deliberately accept much higher risks. For example, crewed spaceflight is extremely dangerous, even with decades of engineering experience and billions of dollars in safety efforts. NASA’s threshold level of acceptable risk for a single mission is a 1 in 270 chance of killing the crew. Even then, the actual failure rate of crewed launches is closer to 1%. Everyone involved is aware of the risks, and decides that the work they’re doing is worth it.
We’re almost ready to translate some of these lessons to artificial intelligence. But first, we have to understand how industries handle risk assessments when the stakes are even higher.
It is one thing to accept a 1 in 10,000 chance of an onsite fatality; it’s quite another to accept that same likelihood of poisoning nearby cities. Sometimes assessors want to consider scenarios that might cause tens, hundreds, or even thousands of deaths, or a similarly massive level of harm. In these cases, assessors will typically run long, detailed assessments that output multiple redundant layers of prevention and mitigation, and they plot the results on an extended risk matrix.
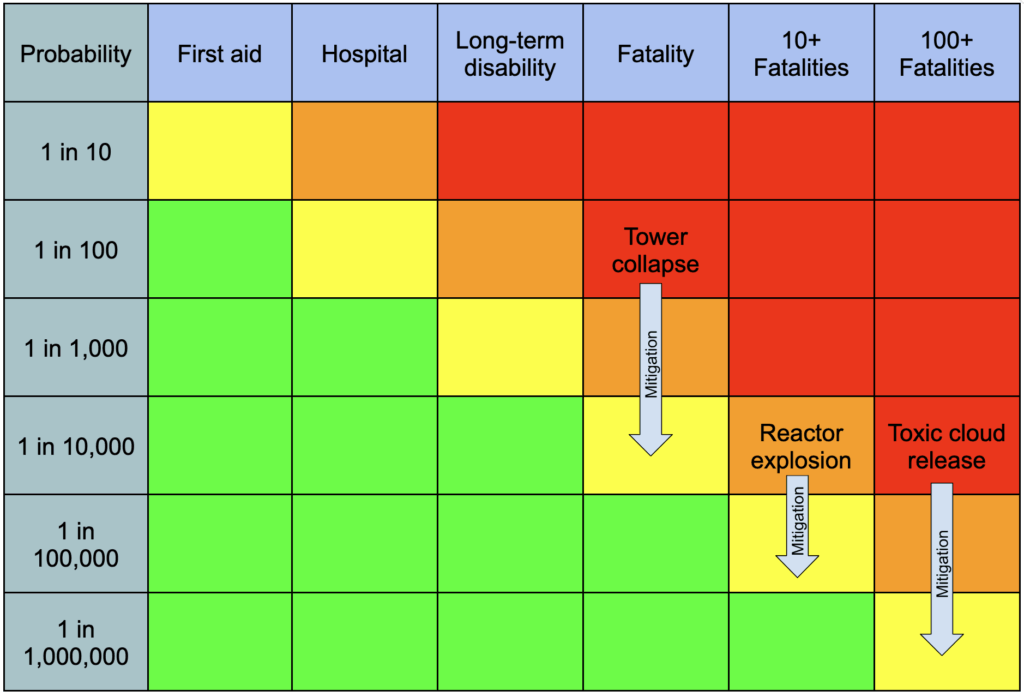
Mature industries recognize that the potentially catastrophic consequences of their operations require a correspondingly extreme effort to prevent. Operations whose safety cannot be guaranteed at the required level of confidence are not begun in the first place.
AI and risk assessment
AI will probably most likely lead to the end of the world, but in the meantime there will be great companies. – Sam Altman
Machine learning is not a mature industry.
Neural networks have been around since the 1950s, but it was only recently that they began to form the backbone of a multibillion-dollar push towards smarter-than-human machines. Before ChatGPT, machine learning didn’t particularly need robust risk assessment, because the AIs that could be built didn’t pose a meaningful threat; they weren’t sophisticated enough to design novel pathogens or rival human strategic reasoning.
But times are changing, and it’s not clear how long this will continue to be true.
The field of AI capabilities research is unprepared for these changes. The first attempt at a “responsible scaling framework” is only two years old. Today’s versions are still grossly inadequate, and preliminary attempts to grade frontier labs’ approaches to risk management find them universally lacking.
Admittedly, it’s a uniquely challenging field to assess. Safety and reliability engineers usually have years if not decades of historical data and detailed causal models of industrial processes to use in estimating the likelihood of catastrophe. Frontier AI labs have benchmarks.
It takes an entire ecosystem of third-party evaluators just to come up with tests that measure the capabilities of next-generation AIs. Predicting those capabilities before development is borderline impossible. Efforts are underway to make better methods available, but assessors face an unprecedented challenge even for short-term chemical, biological, radiological, and nuclear (CBRN) risks.
When it comes to the long-term effects of smarter-than-human AI, traditional risk assessment methods mostly fail. Still, there are some concepts from reliability engineering that I’ve found to be useful intuition pumps for thinking about AI.
Hidden and evident failures
For example, reliability engineering makes a distinction between evident failures and hidden failures.
An evident failure becomes apparent to operators in the normal course of operation. If you get a flat tire while driving, you won’t be ignorant of that fact for long. In oil and gas, a large leak or a pump or compressor shutdown is usually an evident failure.
A hidden failure doesn’t become apparent in the normal course of operation. If your spare tire goes flat, you might not notice until you need it. In a refinery, a rarely-used valve getting stuck open isn’t an obvious problem until someone urgently needs to close it. Then it may become a large problem.
Hidden failures are scary because they make other problems worse. Often, a failure is hidden because the thing that failed isn’t something you need every day. Often, it’s something you only need in an emergency. Often, then, everything seems fine…until there’s an emergency. Then the valve that is supposed to stop fuel flow to a malfunctioning furnace fails to close, and what would be an expensive shutdown is now a deadly conflagration.
Evident failures can be dangerous, too. A massive fireball might be obvious, but that doesn’t make it safe. But evident failures, at least, tend to be corrigible—they provide feedback to operators, who can then investigate and fix the problem. As long as an evident failure isn’t utterly catastrophic, it can usually be fixed in a timely fashion.
How might this distinction translate into AI?
In AI training, there exist some imperfect measures of unwanted behavior. For instance, honeypot tests that put the AI in a simulated environment in which it might have an incentive to deceive its trainers. If the AI takes the bait and acts deceptive, the trainers have learned something important about the AI. Similar tests can sometimes reveal a capacity or tendency to hack the test or copy itself to another server.
Someone newly-introduced to the field of AI training, who has learned the basics of gradient descent, might hit upon the idea of training an AI not to do these things, by optimizing for a tendency to pass such tests. But this also optimizes for a tendency to hack such tests, and a tendency to get better at deception. It has been called the Most Forbidden Technique, and for good reason.
The field of AI has invented, and sometimes employs, a method that trains models to conceal bad behavior. Furthermore, AIs are beginning to grow smart enough to realize deception can serve their goals. In other words, there are forces at work which act to convert evident failures into hidden failures.
My inner engineer finds this fact pretty darn terrifying.
Plotting AI research on a risk matrix
Let us return to the general question of AI and risk assessment. Where might AI risk belong on a risk matrix?
Reliability engineers, like many engineers, have a habit of asking ourselves: What’s the worst that could happen? In more formal terms, we’re looking for the credible scenario that has the highest consequence. In oil and gas, “a reactor explodes” is considered a credible scenario, “a meteor strikes the plant” is not.
It is widely acknowledged that advanced artificial intelligence could cause human extinction. We’ll treat that as our highest-consequence credible scenario.6
What about the likelihood?
Unfortunately — or perhaps fortunately — we don’t have much in the way of historical data on this one. There’s no ability for an engineer to say, “Well, in 9 out of the last 10 cases of humanity building a superintelligent machine, the result was…”
The case that humanity itself could be destroyed by AI largely turns on arguments about the nature and expected behaviors of intelligent minds. Different people buy those arguments to different degrees, and consequently, estimates of the likelihood of human extinction by superintelligent AI are…diverse.
I happen to think the likelihood of this outcome is extremely high. But others disagree, and for this exercise, we don’t need an exact number. We’re just looking to put the risk in the right general bucket. So I’m going to skip the arguments for now, and just use the median estimate from a 2023 survey of artificial intelligence experts: 5-10%.7
(We’re going to need a larger risk matrix.)
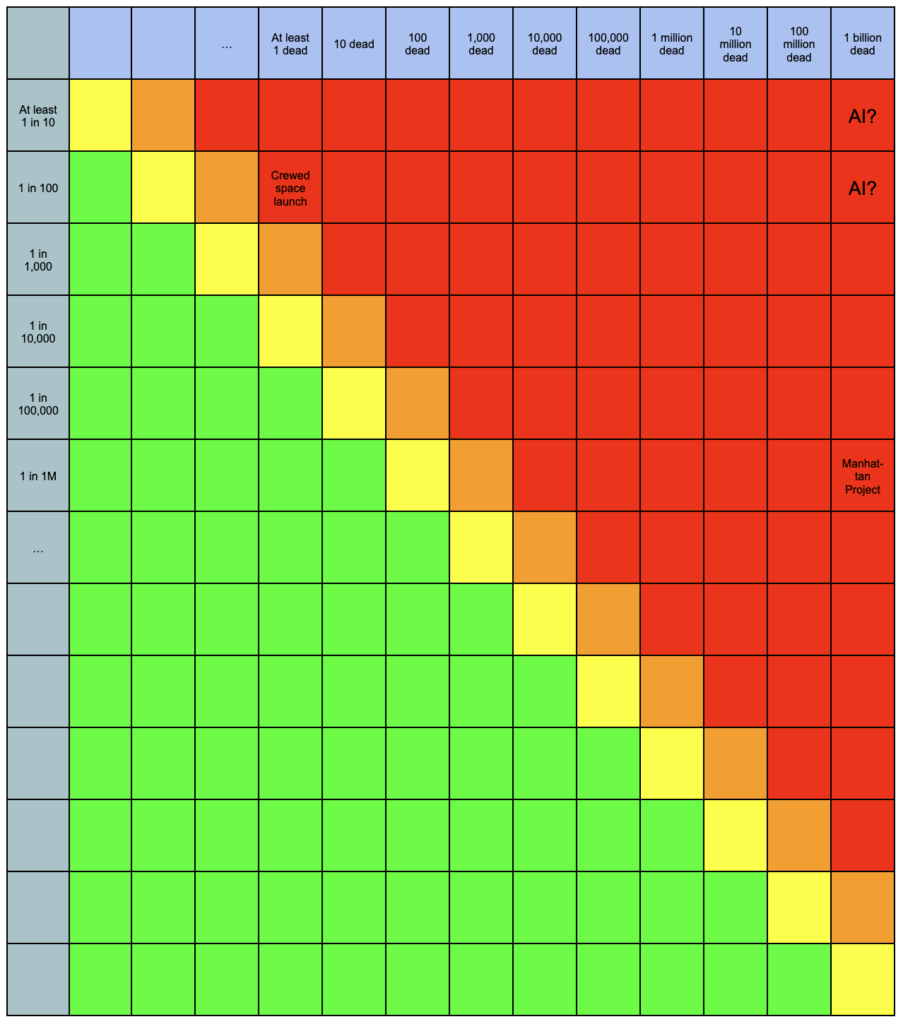
Of course, there are a number of reasons not to take a comparison like this at face value. For one thing, this is looking at the total risk for an entire field, not necessarily the annual risk of a particular project. For another, it’s not considering the commensurate benefits of aligned AI. It’s also not considering potential future lives that could be improved or denied existence by AI.
Nevertheless, it’s a sobering reminder of the sheer magnitude of what’s at stake. Even if we make some questionable assumptions that drop the likelihood of catastrophe a few orders of magnitude, we would still occupy a region of risk-space that perhaps has not been occupied since the days of the Manhattan Project. From the online resources for If Anyone Builds It, Everyone Dies:
The only historical incident we know of where scientists expressed serious concern that some invention might kill literally everyone happened during the Manhattan Project. Some scientists expressed the worry that a nuclear bomb might get so hot that it would start fusing the nitrogen in the atmosphere, turning the atmosphere into a plasma and killing all life on Earth. Fortunately, they had a good understanding of the physical laws at play, and they could do the calculations. Before doing the calculations, one of the scientists — Arthur Compton — decided he would leave the project if the probability of igniting the atmosphere was any higher than3 in 1,000,000. It was better, he thought, to risk the Nazis beating the allies to the bomb than to risk even a 3 in 1,000,000 chance of turning all the air to plasma by his own hands.
That’s about four orders of magnitude lower than 5%.
Several of the heads of leading AI labs have themselves publicly stated or implied likelihoods much, much higher than 3 in 1,000,000. Yet they keep scaling anyway. The field of AI seems to be handling the uncertainty it faces with far greater recklessness than Arthur Compton.
While industrial manufacturing is not a field known for its overflowing altruism, a risk of this magnitude, presented seriously in a mature industry, would prompt an immediate and urgent halt to operations. The seniormost experts available would hammer on the problem relentlessly until their estimates converged on a much, much lower chance of catastrophe. They would draft and revise robust and thorough safety cases which make and defend key load-bearing assumptions.
If I were running this risk assessment in my old job, I’d say we are already well past the “halt, melt, and catch fire” stage.
Prevention and mitigation
Even for those who think the long-term benefits of AI outweigh the risks, it is valuable to think about how we might get out of the red zone, or at least lower the odds of extinction.
While we can and should attempt to mitigate problems driven by narrow AI — economic disruption, CBRN uplift, AI slop generation, etc. — it is a different matter entirely to mitigate a hostile superintelligence. I mostly don’t think we can. It would of course be wise to sharply limit a nascent AI’s ability to interact with the world while studying its internals, but that doesn’t seem to be happening today, and I doubt it would reduce risk by multiple orders of magnitude.
That leaves prevention. Our best chance to avoid extinction by hostile superintelligence is to refrain from building one, and likewise refrain from building self-modifying AI that may grow into a hostile superintelligence.
One way to do this is to figure out the fundamental science of cognition, letting us predict how a given artificial mind will behave and alter its motives directly. A clear demonstration of this technical capacity might be worth an OOM or two of risk reduction, assuming that capacity were actually employed by anyone trying to scale up AI capabilities. Unfortunately, humanity doesn’t seem to be on track to master the relevant science within the next few years.
So in practice, preventing hostile superintelligence means refraining from building superintelligence at all until humanity has built up the collective expertise to do so safely. Efforts to secure international agreement on this point seem, to my risk assessor’s eye, to be the most cost-effective options available.
Residual risk
As a refresher, it is common practice in mature industries to share several key pieces of information with stakeholders and decision-makers:
- The unmitigated or inherent risk, which corresponds to the estimated likelihood and consequence of a bad outcome in the default case if nothing is done;
- A proposed action or set of actions which individually or collectively lower the risk; and
- The mitigated or residual risk, which corresponds to the estimated risk after accounting for these proposed actions.
We’ve covered the first two bullets, the inherent risk (extraordinarily high) and some proposed tasks (study AI cognition, halt frontier AI development). The next obvious question is: How much risk reduction might these tasks buy us?
Engineers and managers know it’s impossible to completely eliminate risk. But you can spend various resources to reduce risk, and the residual risk is what’s left over when you do. Residual risk is extremely important; it tells you how much risk you’re carrying at the end of the day. The difference between inherent risk and residual risk is also important; it tells you how much value you’re getting out of your actions (or at least, how much you think you’re getting.)
Here’s what a (grossly oversimplified) annual budget plan might look like, at a major refinery:8

Applying the same rationale to AI risk, I would very roughly expect that an international ban on superintelligence buys us an OOM or two of risk reduction, and a massive investment in alignment research buys us a further OOM. This still doesn’t bring us to the Arthur Compton standard of three-in-a-million chance of extinction, and I don’t honestly think we can get there, but it’s still worlds better than the current situation.
What about the major AI labs? What residual risk do they think they are accepting on humanity’s behalf?
Well…I don’t know. As far as I’m aware, no major AI lab has publicized anything remotely resembling a concrete estimate of residual risk from their work.
Now, most companies don’t publicly share their internal risk estimates. It’d be bad press no matter what the numbers say. But when a company is literally gambling with the lives of everyone on Earth, but insists that their responsible scaling plans acceptably lower the risk…I think it is reasonable to insist in turn that they explain what residual risk they believe they are implicitly accepting, and what makes them so sure.
- In theory, any consequence can be measured in money if you are willing to put a price on it. Many industries choose not to do so, or do so in roundabout ways, for reasons I won’t get into here.
- Strictly speaking, these are buckets including, for example, all likelihoods between 1 in 100 and 1 in 10. The drawing is simplified for ease of viewing.
- These are all real risks, but the probabilities are made up. In reality, there’s often a long, involved process for generating final probabilities.
- Companies will typically exhaust every possible option, often including motivated reasoning, to avoid getting to this point.
- For the sake of simplicity, I’m deliberately ignoring a lot of factors, such as the effect of summing or “aggregating” multiple risks or dividing them up across many workers, or the effect of mitigations like wearing a seat belt.
- Yes, I know, it could technically get worse.
- The median was either 5% or 10% depending on how the question was asked.
- All of these examples are made up. Please do not try to run a refinery with these numbers.