
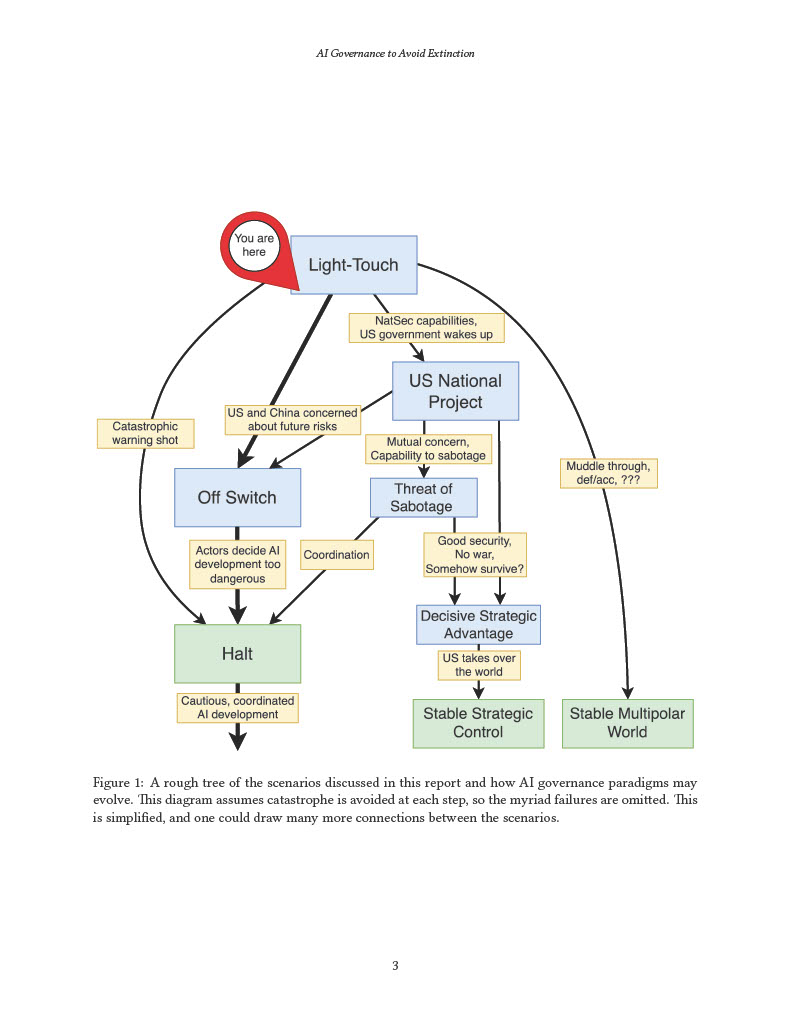





MIRI’s current focus is on attempting to halt the development of increasingly general AI models, via discussions with policymakers about the extreme risks artificial superintelligence poses. Our technical governance research explores the technical questions that bear on these regulatory and policy goals.
This AI governance research agenda lays out our view of the strategic landscape and actionable research questions that, if answered, would provide important insight on how to reduce catastrophic and extinction risks from AI.
AI evaluations are an important component of the AI governance toolkit, underlying current approaches to safety cases for preventing catastrophic risks. Our paper examines what these evaluations can and cannot tell us. Evaluations can establish lower bounds on AI capabilities and assess certain misuse risks given sufficient effort from evaluators.
Unfortunately, evaluations face fundamental limitations that cannot be overcome within the current paradigm. These include an inability to establish upper bounds on capabilities, reliably forecast future model capabilities, or robustly assess risks from autonomous AI systems. This means that while evaluations are valuable tools, we should not rely on them as our main way of ensuring AI systems are safe. We conclude with recommendations for incremental improvements to frontier AI safety, while acknowledging these fundamental limitations remain unsolved.
International agreements about AI development may be required to reduce catastrophic risks from advanced AI systems. However, agreements about such a high-stakes technology must be backed by verification mechanisms—processes or tools that give one party greater confidence that another is following the agreed-upon rules, typically by detecting violations. This report gives an overview of potential verification approaches for three example policy goals, aiming to demonstrate how countries could practically verify claims about each other’s AI development and deployment. The focus is on international agreements and state-involved AI development, but these approaches could also be applied to domestic regulation of companies. While many of the ideal solutions for verification are not yet technologically feasible, we emphasize that increased access (e.g., physical inspections of data centers) can often substitute for these technical approaches, given sufficient political will from the relevant actors. Therefore, we remain hopeful that significant political will could enable ambitious international coordination, with strong verification mechanisms, to reduce catastrophic AI risks.
AI alignment research aims to solve the technical problems involved in ensuring that smarter-than-human AI can be built and deployed without causing an extinction-level catastrophe.
For most of MIRI’s 20+ year history, AI alignment research was our major focus. In 2024, however, we announced a strategy pivot: alignment research at MIRI and in the larger field had gone too slowly, and we now believed that this research was extremely unlikely to succeed in time to prevent an unprecedented catastrophe.
As a consequence, our recent work has focused on identifying and communicating policy solutions to AI risk. We continue to do some AI alignment research, but this is now a fairly small part of our activities.
You can learn more about our past work in AI alignment by reviewing some of our papers
As AI systems grow in intelligence and capability, some of their available options may allow them to resist intervention by their programmers. We call an AI system “corrigible” if it cooperates with what its creators regard as a corrective intervention, despite default incentives for rational agents to resist attempts to shut them down or modify their preferences. We introduce the notion of corrigibility and analyze utility functions that attempt to make an agent shut down safely if a shut-down button is pressed, while avoiding incentives to prevent the button from being pressed or cause the button to be pressed, and while ensuring propagation of the shut-down behavior as it creates new subsystems or self-modifies.
We present a computable algorithm that assigns probabilities to every logical statement in a given formal language, and refines those probabilities over time. We show that it satisfies a number of intuitive desiderata, and show that these properties follow from a logical induction criterion, which is motivated by a series of stock trading analogies. Roughly speaking, each logical sentence φ is associated with a stock that is worth $1 per share if φ is true and nothing otherwise, and we interpret the belief-state of a logically uncertain reasoner as a set of market prices, where Pn(φ) = 50% means that on day n, shares of φ may be bought or sold from the reasoner for 50¢. The logical induction criterion says (very roughly) that there should not be any polynomial-time computable trading strategy with finite risk tolerance that earns unbounded profits in that market over time.
Recent work has suggested that a number of results in classical game theory, where it is a commonplace that mutual defection is rational, might fail to generalize to settings where agents have strong guarantees about each other’s conditional behavior. We demonstrate that robust cooperative equilibria exist for bounded agents. In the process, we prove a new generalization of Löb’s theorem, and therefore of Gödel’s second incompleteness theorem. This parametric version of Löb’s theorem holds for proofs that can be written out in n or fewer characters, where the parameter n can be set to any number.