
A background note:
It’s often the case that people are slow to abandon obsolete playbooks in response to a novel challenge. And AGI is certainly a very novel challenge.
Italian general Luigi Cadorna offers a memorable historical example. In the Isonzo Offensive of World War I, Cadorna lost hundreds of thousands of men in futile frontal assaults against enemy trenches defended by barbed wire and machine guns. As morale plummeted and desertions became epidemic, Cadorna began executing his own soldiers en masse, in an attempt to cure the rest of their “cowardice.” The offensive continued for 2.5 years.
Cadorna made many mistakes, but foremost among them was his refusal to recognize that this war was fundamentally unlike those that had come before. Modern weaponry had forced a paradigm shift, and Cadorna’s instincts were not merely miscalibrated—they were systematically broken. No number of small, incremental updates within his obsolete framework would be sufficient to meet the new challenge.
Other examples of this type of mistake include the initial response of the record industry to iTunes and streaming; or, more seriously, the response of most Western governments to COVID-19.
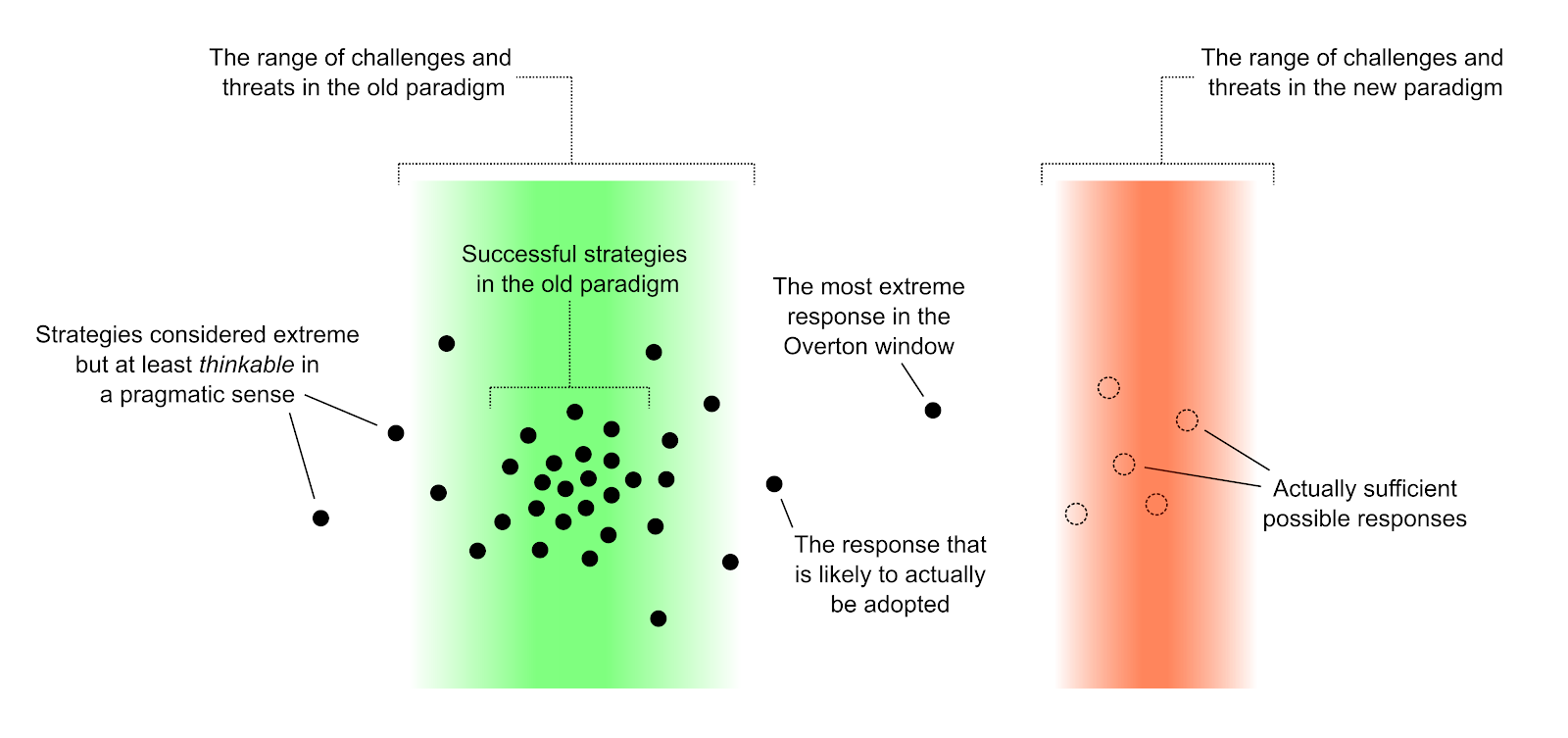
As usual, the real challenge of reference class forecasting is figuring out which reference class the thing you’re trying to model belongs to.
For most problems, rethinking your approach from the ground up is wasteful and unnecessary, because most problems have a similar causal structure to a large number of past cases. When the problem isn’t commensurate with existing strategies, as in the case of AGI, you need a new playbook.
I’ve sometimes been known to complain, or in a polite way scream in utter terror, that “there is no good guy group in AGI”, i.e., if a researcher on this Earth currently wishes to contribute to the common good, there are literally zero projects they can join and no project close to being joinable. In its present version, this document is an informal response to an AI researcher who asked me to list out the qualities of such a “good project”.
In summary, a “good project” needs:
- Trustworthy command: A trustworthy chain of command with respect to both legal and pragmatic control of the intellectual property (IP) of such a project; a running AGI being included as “IP” in this sense.
- Research closure: The organizational ability to close and/or silo IP to within a trustworthy section and prevent its release by sheer default.
- Strong opsec: Operational security adequate to prevent the proliferation of code (or other information sufficient to recreate code within e.g. 1 year) due to e.g. Russian intelligence agencies grabbing the code.
- Common good commitment: The project’s command and its people must have a credible commitment to both short-term and long-term goodness. Short-term goodness comprises the immediate welfare of present-day Earth; long-term goodness is the achievement of transhumanist astronomical goods.
- Alignment mindset: Somebody on the project needs deep enough security mindset plus understanding of AI cognition that they can originate new, deep measures to ensure AGI alignment; and they must be in a position of technical control or otherwise have effectively unlimited political capital. Everybody on the project needs to understand and expect that aligning an AGI will be terrifically difficult and terribly dangerous.
- Requisite resource levels: The project must have adequate resources to compete at the frontier of AGI development, including whatever mix of computational resources, intellectual labor, and closed insights are required to produce a 1+ year lead over less cautious competing projects.
I was asked what would constitute “minimal, adequate, and good” performance on each of these dimensions. I tend to divide things sharply into “not adequate” and “adequate” but will try to answer in the spirit of the question nonetheless.
Trustworthy command
Token: Not having pragmatic and legal power in the hands of people who are opposed to the very idea of trying to align AGI, or who want an AGI in every household, or who are otherwise allergic to the easy parts of AGI strategy.
E.g.: Larry Page begins with the correct view that cosmopolitan values are good, speciesism is bad, it would be wrong to mistreat sentient beings just because they’re implemented in silicon instead of carbon, and so on. But he then proceeds to reject the idea that goals and capabilities are orthogonal, that instrumental strategies are convergent, and that value is complex and fragile. As a consequence, he expects AGI to automatically be friendly, and is liable to object to any effort to align AI as an attempt to keep AI “chained up”.
Or, e.g.: As of December 2015, Elon Musk not only wasn’t on board with closure, but apparently wanted to open-source superhumanly capable AI.
Elon Musk is not in his own person a majority of OpenAI’s Board, but if he can pragmatically sway a majority of that Board then this measure is not being fulfilled even to a token degree.
(Update: Elon Musk stepped down from the OpenAI Board in February 2018.)
Improving: There’s a legal contract which says that the Board doesn’t control the IP and that the alignment-aware research silo does.
Adequate: The entire command structure including all members of the finally governing Board are fully aware of the difficulty and danger of alignment. The Board will not object if the technical leadership have disk-erasure measures ready in case the Board suddenly decides to try to open-source the AI anyway.
Excellent: Somehow no local authority poses a risk of stepping in and undoing any safety measures, etc. I have no idea what incremental steps could be taken in this direction that would not make things worse. If e.g. the government of Iceland suddenly understood how serious things had gotten and granted sanction and security to a project, that would fit this description, but I think that trying to arrange anything like this would probably make things worse globally because of the mindset it promoted.
Closure
Token: It’s generally understood organizationally that some people want to keep code, architecture, and some ideas a ‘secret’ from outsiders, and everyone on the project is okay with this even if they disagree. In principle people aren’t being pressed to publish their interesting discoveries if they are obviously capabilities-laden; in practice, somebody always says “but someone else will probably publish a similar idea 6 months later” and acts suspicious of the hubris involved in thinking otherwise, but it remains possible to get away with not publishing at moderate personal cost.
Improving: A subset of people on the project understand why some code, architecture, lessons learned, et cetera must be kept from reaching the general ML community if success is to have a probability significantly greater than zero (because tradeoffs between alignment and capabilities make the challenge unwinnable if there isn’t a project with a reasonable-length lead time). These people have formed a closed silo within the project, with the sanction and acceptance of the project leadership. It’s socially okay to be conservative about what counts as potentially capabilities-laden thinking, and it’s understood that worrying about this is not a boastful act of pride or a trick to get out of needing to write papers.
Adequate: Everyone on the project understands and agrees with closure. Information is siloed whenever not everyone on the project needs to know it.
Opsec
Token: Random people are not allowed to wander through the building.
Improving: Your little brother cannot steal the IP. Stuff is encrypted. Siloed project members sign NDAs.
Adequate: Major governments cannot silently and unnoticeably steal the IP without a nonroutine effort. All project members undergo government-security-clearance-style screening. AGI code is not running on AWS, but in an airgapped server room. There are cleared security guards in the server room.
Excellent: Military-grade or national-security-grade security. (It’s hard to see how attempts to get this could avoid being counterproductive, considering the difficulty of obtaining trustworthy command and common good commitment with respect to any entity that can deploy such force, and the effect that trying would have on general mindsets.)
Common good commitment
Token: Project members and the chain of command are not openly talking about how dictatorship is great so long as they get to be the dictator. The project is not directly answerable to Trump or Putin. They say vague handwavy things about how of course one ought to promote democracy and apple pie (applause) and that everyone ought to get some share of the pot o’ gold (applause).
Improving: Project members and their chain of command have come out explicitly in favor of being nice to people and eventually building a nice intergalactic civilization. They would release a cancer cure if they had it, their state of deployment permitting, and they don’t seem likely to oppose incremental steps toward a postbiological future and the eventual realization of most of the real value at stake.
Adequate: Project members and their chain of command have an explicit commitment to something like coherent extrapolated volition as a long-run goal, AGI tech permitting, and otherwise the careful preservation of values and sentient rights through any pathway of intelligence enhancement. In the short run, they would not do everything that seems to them like a good idea, and would first prioritize not destroying humanity or wounding its spirit with their own hands. (E.g., if Google or Facebook consistently thought like this, they would have become concerned a lot earlier about social media degrading cognition.) Real actual moral humility with policy consequences is a thing.
Alignment mindset
Token: At least some people in command sort of vaguely understand that AIs don’t just automatically do whatever the alpha male in charge of the organization wants to have happen. They’ve hired some people who are at least pretending to work on that in a technical way, not just “ethicists” to talk about trolley problems and which monkeys should get the tasty banana.
Improving: The technical work output by the “safety” group is neither obvious nor wrong. People in command have ordinary paranoia about AIs. They expect alignment to be somewhat difficult and to take some extra effort. They understand that not everything they might like to do, with the first AGI ever built, is equally safe to attempt.
Adequate: The project has realized that building an AGI is mostly about aligning it. Someone with full security mindset and deep understanding of AGI cognition as cognition has proven themselves able to originate new deep alignment measures, and is acting as technical lead with effectively unlimited political capital within the organization to make sure the job actually gets done. Everyone expects alignment to be terrifically hard and terribly dangerous and full of invisible bullets whose shadow you have to see before the bullet comes close enough to hit you. They understand that alignment severely constrains architecture and that capability often trades off against transparency. The organization is targeting the minimal AGI doing the least dangerous cognitive work that is required to prevent the next AGI project from destroying the world. The alignment assumptions have been reduced into non-goal-valent statements, have been clearly written down, and are being monitored for their actual truth.
Alignment mindset is fundamentally difficult to obtain for a project because Graham’s Design Paradox applies. People with only ordinary paranoia may not be able to distinguish the next step up in depth of cognition, and happy innocents cannot distinguish useful paranoia from suits making empty statements about risk and safety. They also tend not to realize what they’re missing. This means that there is a horrifically strong default that when you persuade one more research-rich person or organization or government to start a new project, that project will have inadequate alignment mindset unless something extra-ordinary happens. I’ll be frank and say relative to the present world I think this essentially has to go through trusting me or Nate Soares to actually work, although see below about Paul Christiano. The lack of clear person-independent instructions for how somebody low in this dimension can improve along this dimension is why the difficulty of this dimension is the real killer.
If you insisted on trying this the impossible way, I’d advise that you start by talking to a brilliant computer security researcher rather than a brilliant machine learning researcher.
Resources
Token: The project has a combination of funding, good researchers, and computing power which makes it credible as a beacon to which interested philanthropists can add more funding and other good researchers interested in aligned AGI can join. E.g., OpenAI would qualify as this if it were adequate on the other 5 dimensions.
Improving: The project has size and quality researchers on the level of say Facebook’s AI lab, and can credibly compete among the almost-but-not-quite biggest players. When they focus their attention on an unusual goal, they can get it done 1+ years ahead of the general field so long as Demis doesn’t decide to do it first. I expect e.g. the NSA would have this level of “resources” if they started playing now but didn’t grow any further.
Adequate: The project can get things done with a 2-year lead time on anyone else, and it’s not obvious that competitors could catch up even if they focused attention there. DeepMind has a great mass of superior people and unshared tools, and is the obvious candidate for achieving adequacy on this dimension; though they would still need adequacy on other dimensions, and more closure in order to conserve and build up advantages. As I understand it, an adequate resource advantage is explicitly what Demis was trying to achieve, before Elon blew it up, started an openness fad and an arms race, and probably got us all killed. Anyone else trying to be adequate on this dimension would need to pull ahead of DeepMind, merge with DeepMind, or talk Demis into closing more research and putting less effort into unalignable AGI paths.
Excellent: There’s a single major project which a substantial section of the research community understands to be The Good Project that good people join, with competition to it deemed unwise and unbeneficial to the public good. This Good Project is at least adequate along all the other dimensions. Its major competitors lack either equivalent funding or equivalent talent and insight. Relative to the present world it would be extremely difficult to make any project like this exist with adequately trustworthy command and alignment mindset, and failed attempts to make it exist run the risk of creating still worse competitors developing unaligned AGI.
Unrealistic: There is a single global Manhattan Project which is somehow not answerable to non-common-good command such as Trump or Putin or the United Nations Security Council. It has orders of magnitude more computing power and smart-researcher-labor than anyone else. Something keeps other AGI projects from arising and trying to race with the giant project. The project can freely choose transparency in all transparency-capability tradeoffs and take an extra 10+ years to ensure alignment. The project is at least adequate along all other dimensions. This is how our distant, surviving cousins are doing it in their Everett branches that diverged centuries earlier towards more competent civilizational equilibria. You cannot possibly cause such a project to exist with adequately trustworthy command, alignment mindset, and common-good commitment, and you should therefore not try to make it exist, first because you will simply create a still more dire competitor developing unaligned AGI, and second because if such an AGI could be aligned it would be a hell of an s-risk given the probable command structure. People who are slipping sideways in reality fantasize about being able to do this.
Further Remarks
A project with “adequate” closure and a project with “improving” closure will, if joined, aggregate into a project with “improving” (aka: inadequate) closure where the closed section is a silo within an open organization. Similar remarks apply along other dimensions. The aggregate of a project with NDAs, and a project with deeper employee screening, is a combined project with some unscreened people in the building and hence “improving” opsec.
“Adequacy” on the dimensions of closure and opsec is based around my mainline-probability scenario where you unavoidably need to spend at least 1 year in a regime where the AGI is not yet alignable on a minimal act that ensures nobody else will destroy the world shortly thereafter, but during that year it’s possible to remove a bunch of safeties from the code, shift transparency-capability tradeoffs to favor capability instead, ramp up to full throttle, and immediately destroy the world.
During this time period, leakage of the code to the wider world automatically results in the world being turned into paperclips. Leakage of the code to multiple major actors such as commercial espionage groups or state intelligence agencies seems to me to stand an extremely good chance of destroying the world because at least one such state actor’s command will not reprise the alignment debate correctly and each of them will fear the others.
I would also expect that, if key ideas and architectural lessons-learned were to leak from an insufficiently closed project that would otherwise have actually developed alignable AGI, it would be possible to use 10% as much labor to implement a non-alignable world-destroying AGI in a shorter timeframe. The project must be closed tightly or everything ends up as paperclips.
“Adequacy” on common good commitment is based on my model wherein the first task-directed AGI continues to operate in a regime far below that of a real superintelligence, where many tradeoffs have been made for transparency over capability and this greatly constrains self-modification.
This task-directed AGI is not able to defend against true superintelligent attack. It cannot monitor other AGI projects in an unobtrusive way that grants those other AGI projects a lot of independent freedom to do task-AGI-ish things so long as they don’t create an unrestricted superintelligence. The designers of the first task-directed AGI are barely able to operate it in a regime where the AGI doesn’t create an unaligned superintelligence inside itself or its environment. Safe operation of the original AGI requires a continuing major effort at supervision. The level of safety monitoring of other AGI projects required would be so great that, if the original operators deemed it good that more things be done with AGI powers, it would be far simpler and safer to do them as additional tasks running on the original task-directed AGI. Therefore: Everything to do with invocation of superhuman specialized general intelligence, like superhuman science and engineering, continues to have a single effective veto point.
This is also true in less extreme scenarios where AGI powers can proliferate, but must be very tightly monitored, because no aligned AGI can defend against an unconstrained superintelligence if one is deliberately or accidentally created by taking off too many safeties. Either way, there is a central veto authority that continues to actively monitor and has the power to prevent anyone else from doing anything potentially world-destroying with AGI.
This in turn means that any use of AGI powers along the lines of uploading humans, trying to do human intelligence enhancement, or building a cleaner and more stable AGI to run a CEV, would be subject to the explicit veto of the command structure operating the first task-directed AGI. If this command structure does not favor something like CEV, or vetoes transhumanist outcomes from a transparent CEV, or doesn’t allow intelligence enhancement, et cetera, then all future astronomical value can be permanently lost and even s-risks may apply.
A universe in which 99.9% of the sapient beings have no civil rights because way back on Earth somebody decided or voted that emulations weren’t real people, is a universe plausibly much worse than paperclips. (I would see as self-defeating any argument from democratic legitimacy that ends with almost all sapient beings not being able to vote.)
If DeepMind closed to the silo level, put on adequate opsec, somehow gained alignment mindset within the silo, and allowed trustworthy command of that silo, then in my guesstimation it might be possible to save the Earth (we would start to leave the floor of the logistic success curve).
OpenAI seems to me to be further behind than DeepMind along multiple dimensions. OAI is doing significantly better “safety” research, but it is all still inapplicable to serious AGI, AFAIK, even if it’s not fake / obvious. I do not think that either OpenAI or DeepMind are out of the basement on the logistic success curve for the alignment-mindset dimension. It’s not clear to me from where I sit that the miracle required to grant OpenAI a chance at alignment success is easier than the miracle required to grant DeepMind a chance at alignment success. If Greg Brockman or other decisionmakers at OpenAI are not totally insensible, neither is Demis Hassabis. Both OAI and DeepMind have significant metric distance to cross on Common Good Commitment; this dimension is relatively easier to max out, but it’s not maxed out just by having commanders vaguely nodding along or publishing a mission statement about moral humility, nor by a fragile political balance with some morally humble commanders and some morally nonhumble ones. If I had a ton of money and I wanted to get a serious contender for saving the Earth out of OpenAI, I’d probably start by taking however many OpenAI researchers could pass screening and refounding a separate organization out of them, then using that as the foundation for further recruiting.
I have never seen anyone except Paul Christiano try what I would consider to be deep macro alignment work. E.g. if you look at Paul’s AGI scheme there is a global alignment story with assumptions that can be broken down, and the idea of exact human imitation is a deep one rather than a shallow defense–although I don’t think the assumptions have been broken down far enough; but nobody else knows they even ought to be trying to do anything like that. I also think Paul’s AGI scheme is orders-of-magnitude too costly and has chicken-and-egg alignment problems. But I wouldn’t totally rule out a project with Paul in technical command, because I would hold out hope that Paul could follow along with someone else’s deep security analysis and understand it in-paradigm even if it wasn’t his own paradigm; that Paul would suggest useful improvements and hold the global macro picture to a standard of completeness; and that Paul would take seriously how bad it would be to violate an alignment assumption even if it wasn’t an assumption within his native paradigm. Nobody else except myself and Paul is currently in the arena of comparison. If we were both working on the same project it would still have unnervingly few people like that. I think we should try to get more people like this from the pool of brilliant young computer security researchers, not just the pool of machine learning researchers. Maybe that’ll fail just as badly, but I want to see it tried.
I doubt that it is possible to produce a written scheme for alignment, or any other kind of fixed advice, that can be handed off to a brilliant programmer with ordinary paranoia and allow them to actually succeed. Some of the deep ideas are going to turn out to be wrong, inapplicable, or just plain missing. Somebody is going to have to notice the unfixable deep problems in advance of an actual blowup, and come up with new deep ideas and not just patches, as the project goes on.