Aligning advanced AI with human interests
MIRI’s mission is to ensure that the creation of smarter-than-human intelligence has
a positive impact. We aim to make advanced intelligent machines behave as
we intend even in the absence of immediate human supervision.
Realistic World-Models
How should a general reasoner mathematically model states of the physical world?
MIRI focuses on AI approaches that can be made transparent (e.g., precisely specified decision algorithms, not genetic algorithms), so that humans can understand why the AIs behave as they do. For safety purposes, a mathematical equation defining general intelligence is more desirable than an impressive but poorly-understood code kludge.
Following this approach, the realistic world-models open problems ask how artificial agents should perform scientific inference. We are particularly interested in formally specifying world-modeling that allows the agent’s physical state and the programmer’s desired outcomes to be located in the model.
Formalizing Two Problems of Realistic World-Models
 An intelligent agent embedded within the real world must reason about an environment which is larger than the agent, and learn how to achieve goals in that environment. We discuss attempts to formalize two problems: one of induction, where an agent must use sensory data to infer a universe which embeds (and computes) the agent, and one of interaction, where an agent must learn to achieve complex goals in the universe. We review related problems formalized by Solomonoff and Hutter, and explore challenges that arise when attempting to formalize these problems in a setting where the agent is embedded within the environment.
An intelligent agent embedded within the real world must reason about an environment which is larger than the agent, and learn how to achieve goals in that environment. We discuss attempts to formalize two problems: one of induction, where an agent must use sensory data to infer a universe which embeds (and computes) the agent, and one of interaction, where an agent must learn to achieve complex goals in the universe. We review related problems formalized by Solomonoff and Hutter, and explore challenges that arise when attempting to formalize these problems in a setting where the agent is embedded within the environment.
Ontological Crises in Artificial Agents’ Value Systems
 Decision-theoretic agents predict and evaluate the results of their actions using a model of their environment. An agent’s goal, or utility function, may also be specified in terms of the entities within its model. If the agent may upgrade or replace its model, it faces a crisis: the agent’s original goal may not be well-defined with respect to its new model. This crisis must be resolved before the agent can make plans towards achieving its goals. We show a solution to the problem for a limited class of models, and suggest a way forward for finding solutions for broader classes of models.
Decision-theoretic agents predict and evaluate the results of their actions using a model of their environment. An agent’s goal, or utility function, may also be specified in terms of the entities within its model. If the agent may upgrade or replace its model, it faces a crisis: the agent’s original goal may not be well-defined with respect to its new model. This crisis must be resolved before the agent can make plans towards achieving its goals. We show a solution to the problem for a limited class of models, and suggest a way forward for finding solutions for broader classes of models.
Logical Uncertainty
How should bounded agents reason with uncertainty about the necessary consequences of their decision criteria and beliefs?
Abstract agents are often assumed to be logically omniscient. The largest obstacle to a formal understanding of highly reliable general-purpose agents may be our poor understanding of how agent behavior changes when that assumption ceases to hold.
Fields that will need to be extended to accommodate logical uncertainty range from probability theory and provability theory, which model how agents should ideally revise their beliefs, to decision theory and game theory, which model how agents should ideally calculate the expected utility of their available actions (and the actions of others). Together with realistic world-modeling, we consider these to be general problems for highly reliable agent design.
Questions of Reasoning Under Logical Uncertainty
 A logically uncertain reasoner would be able to reason as if they know both a programming language and a program, without knowing what the program outputs. Most practical reasoning involves some logical uncertainty, but no satisfactory theory of reasoning under logical uncertainty yet exists. A better theory is needed in order to develop the tools necessary to construct highly reliable artificial reasoners. This paper introduces the topic, discusses a number of historical results, and describes a number of open problems.
A logically uncertain reasoner would be able to reason as if they know both a programming language and a program, without knowing what the program outputs. Most practical reasoning involves some logical uncertainty, but no satisfactory theory of reasoning under logical uncertainty yet exists. A better theory is needed in order to develop the tools necessary to construct highly reliable artificial reasoners. This paper introduces the topic, discusses a number of historical results, and describes a number of open problems.
Non-Omniscience, Probabilistic Inference, and Metamathematics
 We suggest a tractable algorithm for assigning probabilities to sentences of first-order logic and updating those probabilities on the basis of observations. The core technical difficulty is relaxing the constraints of logical consistency in a way that is appropriate for bounded reasoners, without sacrificing the ability to make useful logical inferences or update correctly on evidence.
We suggest a tractable algorithm for assigning probabilities to sentences of first-order logic and updating those probabilities on the basis of observations. The core technical difficulty is relaxing the constraints of logical consistency in a way that is appropriate for bounded reasoners, without sacrificing the ability to make useful logical inferences or update correctly on evidence.
Using this framework, we discuss formalizations of some issues in the epistemology of mathematics. We show how mathematical theories can be understood as latent structure constraining physical observations, and consequently how realistic observations can provide evidence about abstract mathematical facts.
Toward Idealized Decision Theory
 Standard decision procedures are not well-specified enough to be instantiated as algorithms. These procedures also tend to be inconsistent under reflection: an agent that initially uses causal decision theory will regret doing so, and will change its own decision procedure if able.
Standard decision procedures are not well-specified enough to be instantiated as algorithms. These procedures also tend to be inconsistent under reflection: an agent that initially uses causal decision theory will regret doing so, and will change its own decision procedure if able.
This paper motivates the study of decision theory as necessary for aligning smarter-than-human artificial systems with human interests. We discuss the shortcomings of two standard formulations of decision theory, and demonstrate that they cannot be used to describe an idealized decision procedure suitable for approximation by AI. We then explore the notions of strategy selection and logical counterfactuals, two recent insights into decision theory that point the way toward promising paths for future research.
Robust Cooperation on the Prisoner’s Dilemma: Program Equilibrium via Provability Logic
 Classical game-theoretic agents defect in the Prisoner’s Dilemma even though mutual cooperation would yield higher utility for both agents. Moshe Tennenholtz showed that if each program is allowed to pass its playing strategy to all other players, some programs can then cooperate on the one-shot prisoner’s dilemma. Program equilibria is Tennenholtz’s term for Nash equilibria in a context where programs can pass their playing strategies to the other players.
Classical game-theoretic agents defect in the Prisoner’s Dilemma even though mutual cooperation would yield higher utility for both agents. Moshe Tennenholtz showed that if each program is allowed to pass its playing strategy to all other players, some programs can then cooperate on the one-shot prisoner’s dilemma. Program equilibria is Tennenholtz’s term for Nash equilibria in a context where programs can pass their playing strategies to the other players.
One weakness of this approach so far has been that any two non-identical programs cannot “recognize” each other for mutual cooperation, even if they make the same decisions in practice. In this paper, provability logic is used to enable a more flexible and secure form of mutual cooperation.
Vingean Reflection: Reliable Reasoning for Self-Improving Agents
 Once artificial agents become able to improve themselves, they may undergo an “intelligence explosion” and quickly surpass human intelligence. In this paper, we discuss one aspect of the challenge of giving self-modifying agents stable, well-understood goals: ensuring that the initial agent’s reasoning about its future versions is reliable, even if these future versions are far more intelligent than the current reasoner. We refer to reasoning of this sort as Vingean reflection.
Once artificial agents become able to improve themselves, they may undergo an “intelligence explosion” and quickly surpass human intelligence. In this paper, we discuss one aspect of the challenge of giving self-modifying agents stable, well-understood goals: ensuring that the initial agent’s reasoning about its future versions is reliable, even if these future versions are far more intelligent than the current reasoner. We refer to reasoning of this sort as Vingean reflection.
The framework of expected utility maximization, commonly used to model rational agents, fails for self-improving agents. Such agents must reason about the behavior of their smarter successors in abstract terms, since if they could predict their actions in detail, they would already be as smart as them. We discuss agents that instead use formal proofs to reason about their successors. While it is unlikely that real-world agents would base their behavior entirely on formal proofs, this appears to be the best currently available formal model of abstract reasoning.
Error Tolerance
How can an advanced AI be made to accept and assist with online debugging and adjustment of its goals?
Rational agents pursuing some goal have an incentive to protect their goal-content. No matter what their current goal is, it will very likely be better served if the agent continues to promote it than if the agent changes goals. This suggests that it may be difficult to improve an AI’s alignment with human interests over time, particularly when the AI is smart enough to model and adapt to its programmers’ goals.
Corrigibility
 As artificially intelligent systems grow in intelligence and capability, some of their available options may allow them to resist intervention by their programmers. We call an AI system “corrigible” if it cooperates with what its creators regard as a corrective intervention, despite default incentives for rational agents to resist attempts to shut them down or modify their preferences. We introduce the notion of corrigibility and analyze utility functions that attempt to make an agent shut down safely if a shut-down button is pressed, while avoiding incentives to prevent the button from being pressed or cause the button to be pressed, and while ensuring propagation of the shut-down behavior as it creates new subsystems or self-modifies. While some proposals are interesting, none have yet been demonstrated to satisfy all of our intuitive desiderata, leaving this simple problem in corrigibility wide-open.
As artificially intelligent systems grow in intelligence and capability, some of their available options may allow them to resist intervention by their programmers. We call an AI system “corrigible” if it cooperates with what its creators regard as a corrective intervention, despite default incentives for rational agents to resist attempts to shut them down or modify their preferences. We introduce the notion of corrigibility and analyze utility functions that attempt to make an agent shut down safely if a shut-down button is pressed, while avoiding incentives to prevent the button from being pressed or cause the button to be pressed, and while ensuring propagation of the shut-down behavior as it creates new subsystems or self-modifies. While some proposals are interesting, none have yet been demonstrated to satisfy all of our intuitive desiderata, leaving this simple problem in corrigibility wide-open.
Value Specification
Given the complexity of human preferences and values, how can an AI be made to acquire the right behavioral goals?
Using training data to teach advanced AI systems what we value looks more promising than trying to code in everything we care about by hand. However, we know very little about how to discern when training data is unrepresentative of the agent’s future environment, or how to ensure that the AI not only learns about our values but accepts them as its own.
The Value Learning Problem
 A superintelligent machine would not automatically act as intended: it will act as programmed, but the fit between human intentions and written code could be poor. We discuss methods by which a system could be constructed to learn what to value. We highlight open problems specific to inductive value learning (from labeled training data), and raise a number of questions about the construction of systems which model the preferences of their operators and act accordingly.
A superintelligent machine would not automatically act as intended: it will act as programmed, but the fit between human intentions and written code could be poor. We discuss methods by which a system could be constructed to learn what to value. We highlight open problems specific to inductive value learning (from labeled training data), and raise a number of questions about the construction of systems which model the preferences of their operators and act accordingly.
Learning What to Value
 Reinforcement learning can only be used in the real world to define agents whose goal is to maximize expected rewards, and since this goal does not match with human goals, AGIs based on reinforcement learning will often work at cross-purposes to us. To solve this problem, we define agents that can be designed to learn and maximize any initially unknown utility function so long as we provide them with an idea of what constitutes evidence about that utility function.
Reinforcement learning can only be used in the real world to define agents whose goal is to maximize expected rewards, and since this goal does not match with human goals, AGIs based on reinforcement learning will often work at cross-purposes to us. To solve this problem, we define agents that can be designed to learn and maximize any initially unknown utility function so long as we provide them with an idea of what constitutes evidence about that utility function.
Forecasting
When will high-intelligence machines be invented,
and under what circumstances?
In addition to our mathematical research, MIRI investigates important strategic questions, such as: What can (and can’t) we predict about future AI? How can we improve our forecasting ability? Which interventions available today appear to be the most beneficial, given what little we do know?
Intelligence Explosion Microeconomics
 I.J. Good suggested that a sufficiently advanced machine intelligence could build a smarter version of itself, which could in turn build an even smarter version, and that this process could continue to the point of vastly surpassing human capability. How can we model and test this hypothesis?
I.J. Good suggested that a sufficiently advanced machine intelligence could build a smarter version of itself, which could in turn build an even smarter version, and that this process could continue to the point of vastly surpassing human capability. How can we model and test this hypothesis?
We identify the key issue as returns on cognitive reinvestment—the ability to invest more computing power, faster computers, or improved cognitive algorithms to yield cognitive labor which produces larger brains, faster brains, or better mind designs. Many phenomena have been claimed as evidence for various positions in this debate, from the observed course of hominid evolution to Moore’s Law to the competence over time of chess programs. This paper explores issues that arise when trying to interpret this evidence in light of Good’s hypothesis, and proposes that the next step in this research is to formalize return-on-investment curves, so that each position can formally state which models they hold to be falsified by historical observations.
How We’re Predicting AI—or Failing To

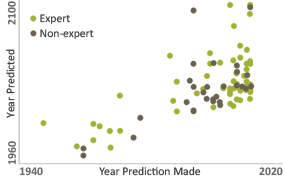 There are strong theoretical reasons to expect timeline forecasts of human-level AI to be quite poor. A database of 95 historical AI timeline forecasts demonstrates that these expectations are borne out in practice: expert predictions contradict each other considerably, and are indistinguishable from non-expert predictions and past failed predictions. Predictions that AI lies 15 to 25 years in the future have consistently been the most common, from experts and non-experts alike.
There are strong theoretical reasons to expect timeline forecasts of human-level AI to be quite poor. A database of 95 historical AI timeline forecasts demonstrates that these expectations are borne out in practice: expert predictions contradict each other considerably, and are indistinguishable from non-expert predictions and past failed predictions. Predictions that AI lies 15 to 25 years in the future have consistently been the most common, from experts and non-experts alike.
Intelligence Explosion: Evidence and Import
 We review the evidence for and against three claims: that (1) there is a substantial chance we will create human-level AI before 2100, that (2) if human-level AI is created, there is a good chance vastly superhuman AI will follow via an “intelligence explosion,” and that (3) an uncontrolled intelligence explosion could destroy everything we value, but a controlled intelligence explosion would benefit humanity enormously if we can achieve it. The paper concludes with recommendations for increasing the odds of a controlled intelligence explosion relative to an uncontrolled intelligence explosion.
We review the evidence for and against three claims: that (1) there is a substantial chance we will create human-level AI before 2100, that (2) if human-level AI is created, there is a good chance vastly superhuman AI will follow via an “intelligence explosion,” and that (3) an uncontrolled intelligence explosion could destroy everything we value, but a controlled intelligence explosion would benefit humanity enormously if we can achieve it. The paper concludes with recommendations for increasing the odds of a controlled intelligence explosion relative to an uncontrolled intelligence explosion.