 Stephen Hsu is Vice-President for Research and Graduate Studies and Professor of Theoretical Physics at Michigan State University. Educated at Caltech and Berkeley, he was a Harvard Junior Fellow and held faculty positions at Yale and the University of Oregon. He was also founder of SafeWeb, an information security startup acquired by Symantec. Hsu is a scientific advisor to BGI and a member of its Cognitive Genomics Lab.
Stephen Hsu is Vice-President for Research and Graduate Studies and Professor of Theoretical Physics at Michigan State University. Educated at Caltech and Berkeley, he was a Harvard Junior Fellow and held faculty positions at Yale and the University of Oregon. He was also founder of SafeWeb, an information security startup acquired by Symantec. Hsu is a scientific advisor to BGI and a member of its Cognitive Genomics Lab.
Luke Muehlhauser: I’d like to start by familiarizing our readers with some of the basic facts relevant to the genetic architecture of cognitive ability, which I’ve drawn from the first half of a presentation you gave in February 2013:
- The human genome consists of about 3 billion base pairs, but humans are very similar to each other, so we only differ from each other on about 3 million of these base pairs.
- Because there’s so much repetition, we could easily store the entire genome of every human on earth (~3mb per genome, compressed).
- Scanning someone’s SNPs costs about $200; scanning their entire genome costs $1000 or more.
- But, genotyping costs are falling so quickly that SNPs may be irrelevant soon, as it’ll be simpler and cheaper to just sequence entire genomes.
- To begin to understand the genetic architecture of cognitive ability, we can compare it to the genetic architecture of height, since the genetic architectures of height and cognitive ability are qualitatively the same.
- For example, (1) height and cognitive ability are relatively stable and reliable traits (in adulthood), meaning that if you measure a person’s height or cognitive ability at multiple times you’ll get roughly the same result each time, (2) height and cognitive ability are valid traits, in that they “measure something real” that is predictive of various life outcome measures like income, (3) both height and cognitive ability are highly heritable, and (4) both height and cognitive ability are highly polygenic, meaning that many different genes contribute to height and cognitive ability.
- All cognitive observables — e.g. vocabulary, digit recall (short term memory), ability to solve math puzzles, spatial rotation ability, cognitive reaction time — appear to be positively correlated. Because of this, we can (lossily) compress the data for how a person scores on different cognitive tests to a single number, which we call IQ, and this single number is predictive of their scores on all cognitive tests, and also life outcome measures like income, educational attainment, job performance, and mortality.
- This contradicts some folk wisdom. E.g. parents often believe that “Johnny’s good at math, so he’s probably not going to be good with words.” But in fact, the data show that math skill is quite predictive of verbal skill, because (roughly) all cognitive abilities are positively correlated.
- By convention, IQ is normally distributed in the population with a mean at 100 and a standard deviation of 15.
- Culturally neutral cognitive tests like progressive matrices are very tightly correlated (0.9) with IQ. So you can estimate someone’s IQ (and hence their verbal ability, spatial rotation ability, short term memory, cognitive reaction time, etc.) pretty well using only one test like Raven’s progressive matrices.
- It’s very difficult to raise one’s score on these cognitive tests with training. In large studies, it looks like thousands of dollars worth of training can raise your score by a small fraction of the standard deviation.
- Additional IQ points do appear to “matter” — even above, say, IQ 145. E.g. the mean IQ of eminent scientists (IQ 160) is much higher than that of average PhDs (IQ 130). Also, in a longitudinal study of children identified as gifted at age 13, the “1 in 10,000”-level children had significantly better life outcomes than the “1 in 100”-level children, even though they generally all received “gifted child” development paths.
One source of details and references for most of this is The Cambridge Handbook of Intelligence.
Before we continue, Stephen, do you have any corrections or clarifications you’d like to make about my summary, or additional sources that you’d like to recommend to our readers?
Stephen Hsu: A couple of comments on the summary, which is excellent:
- Raven’s correlation might not be as high as 0.9 with overall IQ, it might actually be 0.8 or so. These numbers fluctuate around depending on the study. In general two tests might be considered valid “IQ tests” if they correlate at > 0.75 or so with g. This is the case with most standardized tests like ACT, SAT, GRE, etc.
- Mean IQ of participants in the Roe study was quite high, but I doubt that the average among eminent scientists (averaging over all fields) is 160; probably a bit lower like 145. In any case the Roe and SMPY data are sufficient to suggest nontrivial returns to IQ above 130 in STEM.
It seems you understood my talk perfectly well. The answers to your questions may already be in there, but I’m happy to discuss and clarify further.
Luke: Have we identified any genes that are (with high confidence) associated with cognitive ability? What can our history of identifying genes associated with other polygenic traits (e.g. height) tell us about our prospects for identifying genes associated with cognitive ability?
Stephen: Recently the results of a massive GWAS for genes associated with educational attainment were published in Science. Some of the researchers in this large collaboration are reluctant to openly state that the hits are associated with cognitive ability (as opposed to, say, Conscientiousness, which would also positively impact educational success). But if you read the paper carefully you can see that there is good evidence that the alleles are actually associated with cognitive ability (g or IQ).
At the link above you can find a historical graph:
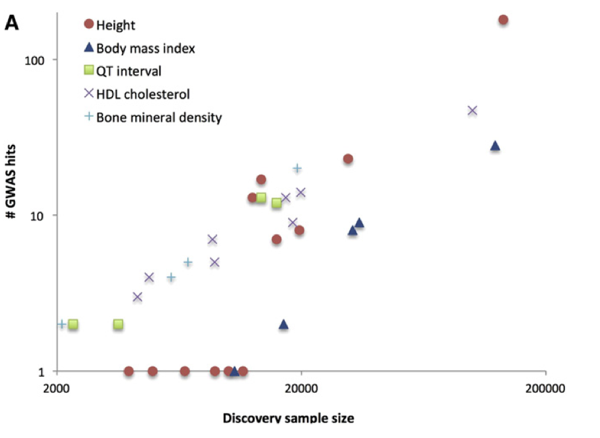
This graph displays the number of GWAS hits versus sample size for height, BMI, etc. Once the minimal sample size to discover the alleles of largest impact (large MAF, large effect size) is exceeded, one generally expects a steady accumulation of new hits at lower MAF / effect size. I expect the same sort of progress for g. (MAF = Minor Allele Frequency. Variants that are common in the population are easier to detect than rare variants.)
We can’t predict the sample size required to obtain most of the additive variance for g (this depends on the details of the distribution of alleles), but I would guess that about a million genotypes together with associated g scores will suffice. When, exactly, we will reach this sample size is unclear, but I think most of the difficulty is in obtaining the phenotype data. Within a few years, over a million people will have been genotyped, but probably we will only have g scores for a small fraction of the individuals.
Luke: Could you describe for us the goals and methods of the work you’re currently doing with BGI?
Stephen: The goal of our cognitive genomics project at BGI is to understand the genetic architecture of human cognition. There are obviously many potential applications of this work, in areas ranging from deep human history (evolution) to drug discovery to genetic engineering. But my primary interest is intellectual.
The methods are straightforward: obtain genotype and phenotype data and look for statistical associations (GWAS). More specifically, we want to determine the parameters of a polygenic model relating genotype to phenotype. (This as yet undetermined set of “fundamental constants” is one of the most interesting few megabytes of information in the biological world.) The leading term in this model is linear (meaning we are guaranteed a certain amount of progress from simple techniques), but eventually we will be interested in nonlinear corrections (epistasis, gene-gene interactions, dominance, etc.) as well.
We started out by looking for high g individuals because, as outliers, they produce more statistical power per dollar of sequencing. The cost of sequencing is still our primary constraint, and will be for at least a few more years. For example, the cost to sequence our 2000 high g volunteers is well into the millions of dollars. I also felt, given my background, that I had reasonable insight into where to find and how to recruit volunteers from the high g tail.
Ultimately, I hope that various genomics labs around the world will collaborate to produce a public data repository with g as one of the phenotype variables.
Link:
Luke: How feasible do you think “iterated embryo selection” will be, over the next several decades, for the amplification of cognitive abilities via genetic selection?
Background for our readers: iterated embryo selection is a plausible future technology that could allow strong genetic selection for intelligence without needing to wait 15-20 years between generations. It was first described in detail in the FAQ for MIRI’s The Uncertain Future project (see Rayhawk et al. 2009), was later described in a book (Miller 2012), and was finally published in a journal in Sparrow (2013).
Stephen: I have no particular insight into specific challenges related to producing gametes from pluripotent stem cells. It’s not my area of expertise. However, I am confident that genomic selection for traits such as g will be possible. I would be surprised if, after analyzing millions of genotype-phenotype pairs, we were not able to produce a predictive model that captures, say, 50% of variance in g. That means, roughly, we might be able to predict g from genotype with standard error of somewhat less than a population standard deviation (e.g., 10 IQ points; note I don’t think the real world “meaning” of g is better defined than within an error of this size). This means that selection on g can proceed relatively efficiently, assuming the basic reproductive technologies are under control.
I think there is good evidence that existing genetic variants in the human population (i.e., alleles affecting intelligence that are found today in the collective world population, but not necessarily in a single person) can be combined to produce a phenotype which is far beyond anything yet seen in human history. This would not surprise an animal or plant breeder — experiments on corn, cows, chickens, drosophila, etc. have shifted population means by many standard deviations (e.g., +30 SD in the case of corn).
Let me add that, in my opinion, each society has to decide for itself (e.g. through democratic process) whether it wants to legalize or forbid activities that amount to genetic engineering. Intelligent people can reasonably disagree as to whether such activity is wise.
Links:
Maxwell’s Demon and genetic engineering
Deleterious variants affecting traits that have been under selection are rare and of small effect
Luke: Work on the genetics of cognitive ability tends to be more controversial than work on the genetics of, say, height. Why do you think that is? Has your work, or the work of your colleagues, been made more difficult because of such issues?
Stephen: Given our difficult history with race there is an understandable discomfort with the idea that cognitive ability is strongly influenced by genetics. In the worst case, it might be found that historically isolated populations of humans differ in their average genetic capacities for cognition, due to variation in allele frequencies. Let me stress that at the moment our understanding of the genetics of intelligence is far too preliminary to reach a firm conclusion on this issue.
At the extremes, there are some academics and social activists who violently oppose any kind of research into the genetics of cognitive ability. Given that the human brain — its operation, construction from a simple genetic blueprint, evolutionary history — is one of the great scientific mysteries of the universe, I cannot understand this point of view.
Luke: What do you think a truly superior human intelligence would be like?
Stephen: I think we already have some hints in this direction. Take the case of John von Neumann, widely regarded as one of the greatest intellects in the 20th century, and a famous polymath. He made fundamental contributions in mathematics, physics, nuclear weapons research, computer architecture, game theory and automata theory.
In addition to his abstract reasoning ability, von Neumann had formidable powers of mental calculation and a photographic memory. In my opinion, genotypes exist that correspond to phenotypes as far beyond von Neumann as he was beyond a normal human.
I have known a great many intelligent people in my life. I knew Planck, von Laue and Heisenberg. Paul Dirac was my brother in law; Leo Szilard and Edward Teller have been among my closest friends; and Albert Einstein was a good friend, too. But none of them had a mind as quick and acute as Jansci [John] von Neumann. I have often remarked this in the presence of those men and no one ever disputed me.
— Nobel Laureate Eugene Wigner
You know, Herb, how much faster I am in thinking than you are. That is how much faster von Neumann is compared to me.
— Nobel Laureate Enrico Fermi to his former PhD student Herb Anderson.
One of his remarkable abilities was his power of absolute recall. As far as I could tell, von Neumann was able on once reading a book or article to quote it back verbatim; moreover, he could do it years later without hesitation. He could also translate it at no diminution in speed from its original language into English. On one occasion I tested his ability by asking him to tell me how The Tale of Two Cities started. Whereupon, without any pause, he immediately began to recite the first chapter and continued until asked to stop after about ten or fifteen minutes.
— Herman Goldstine, mathematician and computer pioneer.
I always thought Von Neumann’s brain indicated that he was from another species, an evolution beyond man,
— Nobel Laureate Hans A. Bethe.
Links:
Luke: Thanks, Stephen!
Did you like this post? You may enjoy our other Conversations posts, including: