October 2015 Newsletter
|
Research updates
General updates
News and links
|
|
Research updates
General updates
News and links
|
 We have released a new paper on logical uncertainty, co-authored by Scott Garrabrant, Siddharth Bhaskar, Abram Demski, Joanna Garrabrant, George Koleszarik, and Evan Lloyd: “Asymptotic logical uncertainty and the Benford test.”
We have released a new paper on logical uncertainty, co-authored by Scott Garrabrant, Siddharth Bhaskar, Abram Demski, Joanna Garrabrant, George Koleszarik, and Evan Lloyd: “Asymptotic logical uncertainty and the Benford test.”
Garrabrant gives some background on his approach to logical uncertainty on the Intelligent Agent Foundations Forum:
The main goal of logical uncertainty is to learn how to assign probabilities to logical sentences which have not yet been proven true or false.
One common approach is to change the question, assume logical omniscience and only try to assign probabilities to the sentences that are independent of your axioms (in hopes that this gives insight to the other problem). Another approach is to limit yourself to a finite set of sentences or deductive rules, and assume logical omniscience on them. Yet another approach is to try to define and understand logical counterfactuals, so you can try to assign probabilities to inconsistent counterfactual worlds.
One thing all three of these approaches have in common is they try to allow (a limited form of) logical omniscience. This makes a lot of sense. We want a system that not only assigns decent probabilities, but which we can formally prove has decent behavior. By giving the system a type of logical omniscience, you make it predictable, which allows you to prove things about it.
However, there is another way to make it possible to prove things about a logical uncertainty system. We can take a program which assigns probabilities to sentences, and let it run forever. We can then ask about whether or not the system eventually gives good probabilities.
At first, it seems like this approach cannot work for logical uncertainty. Any machine which searches through all possible proofs will eventually give a good probability (1 or 0) to any provable or disprovable sentence. To counter this, as we give the machine more and more time to think, we have to ask it harder and harder questions.
We therefore have to analyze the machine’s behavior not on individual sentences, but on infinite sequences of sentences. For example, instead of asking whether or not the machine quickly assigns 1/10 to the probability that the 3↑↑↑↑3rd digit of π is a 5 we look at the sequence:
an:= the probability the machine assigns at timestep 2n to the n↑↑↑↑nth digit of π being 5,
and ask whether or not this sequence converges to 1/10.
Benford’s law is the observation that the first digit in base 10 of various random numbers (e.g., random powers of 3) is likely to be small: the digit 1 comes first about 30% of the time, 2 about 18% of the time, and so on; 9 is the leading digit only 5% of the time. In their paper, Garrabrant et al. pick the Benford test as a concrete example of logically uncertain reasoning, similar to the π example: a machine passes the test iff it consistently assigns the correct subjective probability to “The first digit is a 1.” for the number 3 to the power f(n), where f is a fast-growing function and f(n) cannot be quickly computed.
Garrabrant et al.’s new paper describes an algorithm that passes the Benford test in a nontrivial way by searching for infinite sequences of sentences whose truth-values cannot be distinguished from the output of a weighted coin.
In other news, the papers “Toward idealized decision theory” and “Reflective oracles: A foundation for classical game theory” are now available on arXiv. We’ll be presenting a version of the latter paper with a slightly altered title (“Reflective oracles: A foundation for game theory in artificial intelligence”) at LORI-V next month.
Update June 12, 2016: “Asymptotic logical uncertainty and the Benford test” has been accepted to AGI-16.
Get notified every time a new technical paper is published.
|
Research updates
General updates
News and links
|
Our summer fundraising drive is now finished. We raised a grand total of $631,957, from 263 donors.1 This is an incredible sum, and your support has made this the biggest fundraiser we’ve ever run.
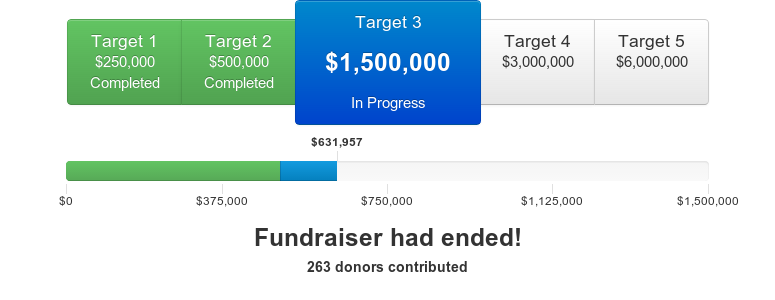
We’ve already been hard at work growing our research team and spinning up new projects, and I’m excited to see what our research team can do this year. Thank you for making our summer fundraising drive so successful!
Today is the final day of MIRI’s summer fundraising drive, and as of this morning, our total stands at $543,373. Our donors’ efforts have made this fundraiser the biggest one we’ve ever run, and we’re hugely grateful.
As our fundraiser nears the finish line, I’d like to update you on the new shape of MIRI’s research team. We’ve been actively recruiting throughout the fundraiser, and we are taking on three new full-time researchers in 2015.
At the beginning of the fundraiser, we had three research fellows on our core team: Eliezer Yudkowsky, Benja Fallenstein, and Patrick LaVictoire. Eliezer is one of MIRI’s co-founders, and Benja joined the team a little over a year ago (in March 2014). Patrick is a newer recruit; he joined in March of 2015. He has a mathematics PhD from U.C. Berkeley, and he has industry experience from Quixey doing applied machine learning and data science. He’s responsible for some important insights into our open problems, and he’s one of the big reasons why our summer workshops have been running so smoothly.
On August 1st, Jessica Taylor became the fourth member of our core research team. She recently completed a master’s degree in computer science at Stanford, where she studied machine learning and probabilistic programming. Jessica is quite interested in AI alignment, and has been working with MIRI in her spare time for many months now. Already, she’s produced some exciting research, and I’m delighted to have her on the core research team.
Meanwhile, over the course of the fundraiser, we’ve been busy expanding the team. Today, I’m happy to announce our three newest hires!
MIRI is a research nonprofit specializing in a poorly-explored set of problems in theoretical computer science. GiveDirectly is a cash transfer service that gives money to poor households in East Africa. What kind of conference would bring together representatives from such disparate organizations — alongside policy analysts, philanthropists, philosophers, and many more?
Effective Altruism Global, which is beginning its Oxford session in a few hours, is that kind of conference. Effective altruism (EA) is a diverse community of do-gooders with a common interest in bringing the tools of science to bear on the world’s biggest problems. EA organizations like GiveDirectly, the Centre for Effective Altruism, and the charity evaluator GiveWell have made a big splash by calling for new standards of transparency and humanitarian impact in the nonprofit sector.
What is MIRI’s connection to effective altruism? In what sense is safety research in artificial intelligence “altruism,” and why do we assign a high probability to this being a critically important area of computer science in the coming decades? I’ll give quick answers to each of those questions below.
Over the past few months, some major media outlets have been spreading concern about the idea that AI might spontaneously acquire sentience and turn against us. Many people have pointed out the flaws with this notion, including Andrew Ng, an AI scientist of some renown:
I don’t see any realistic path from the stuff we work on today—which is amazing and creating tons of value—but I don’t see any path for the software we write to turn evil.
He goes on to say, on the topic of sentient machines:
Computers are becoming more intelligent and that’s useful as in self-driving cars or speech recognition systems or search engines. That’s intelligence. But sentience and consciousness is not something that most of the people I talk to think we’re on the path to.
I say, these objections are correct. I endorse Ng’s points wholeheartedly — I see few pathways via which software we write could spontaneously “turn evil.”
I do think that there is important work we need to do in advance if we want to be able to use powerful AI systems for the benefit of all, but this is not because a powerful AI system might acquire some “spark of consciousness” and turn against us. I also don’t worry about creating some Vulcan-esque machine that deduces (using cold mechanic reasoning) that it’s “logical” to end humanity, that we are in some fashion “unworthy.” The reason to do research in advance is not so fantastic as that. Rather, we simply don’t yet know how to program intelligent machines to reliably do good things without unintended consequences.
The problem isn’t Terminator. It’s “King Midas.” King Midas got exactly what he wished for — every object he touched turned to gold. His food turned to gold, his children turned to gold, and he died hungry and alone.
Powerful intelligent software systems are just that: software systems. There is no spark of consciousness which descends upon sufficiently powerful planning algorithms and imbues them with feelings of love or hatred. You get only what you program.1
Last week, we received several questions from the effective altruist community in response to our fundraising post. Here’s Maxwell Fritz:
[…] My snap reaction to MIRI’s pitches has typically been, “yeah, AI is a real concern. But I have no idea whether MIRI are the right people to work on it, or if their approach to the problem is the right one” [… I]f you agree AI matters, why MIRI?
And here are two more questions in a similar vein, added by Tristan Tager:
[… W]hat can MIRI do? Why should I expect that the MIRI vision and the MIRI team are going to get things done? What exactly can I expect them to get done? […]
But the second and much bigger question is, what would MIRI do that Google wouldn’t? Google has a ton of money, a creative and visionary staff, the world’s best programmers, and a swath of successful products that incorporate some degree of AI — and moreover they recently acquired several AI businesses and formed an AI ethics board. It seems like they’re approaching the same big problem directly rather than theoretically, and have deep pockets, keen minds, and a wealth of hands-on experience.
These are great questions. My answer to “Why MIRI?”, in short, is that MIRI has a brilliant team of researchers focused on the fundamental theoretical research that almost nobody else is pursuing. We’re focused entirely on aligning smarter-than-human AI systems with humane values, for the long haul.
Most academics aren’t working on AI alignment problems yet, and none are doing it full-time. Most industry folks aren’t working on these problems yet, either. I know this because I’m in conversations with a number of them. (The field is large, but it isn’t that large.)
There are quite a few good reasons why academics and industry professionals aren’t working on these problems yet, and I’ll touch on a few of them in turn.
Read more »