
We’re excited to release a new AI governance research agenda from the MIRI Technical Governance Team. With this research agenda, we have two main aims: to describe the strategic landscape of AI development and to catalog important governance research questions. We base the agenda around four high-level scenarios for the geopolitical response to advanced AI development. Our favored scenario involves building the technical, legal, and institutional infrastructure required to internationally restrict dangerous AI development and deployment (which we refer to as an Off Switch), which leads into an internationally coordinated Halt on frontier AI activities at some point in the future.
This blog post is a slightly edited version of the executive summary, you can find the full version here: AI Governance to Avoid Extinction: The Strategic Landscape and Actionable Research Questions
We are also looking for someone to lead our team and work on these problems, please reach out here if you think you’d be a good fit.
The default trajectory of AI development has an unacceptably high likelihood of leading to human extinction. AI companies such as OpenAI, Anthropic, and Google DeepMind aim to develop AI systems that exceed human performance at most cognitive tasks, and many experts think they will succeed in the next few years. This development alone will be one of the most transformative and potentially destabilizing events in human history—similar in scale to the Industrial Revolution. But the most worrisome challenges arise as these systems grow to substantially surpass humanity in all strategically relevant activities, becoming what is often referred to as artificial superintelligence (ASI).
In our view, the field of AI is on track to produce ASI while having little to no understanding of how these systems function and no robust means to steer and control their behavior. AI developers, policymakers, and the public seem radically unprepared for the coming impacts of AI. There is a fraught interplay between the risks posed by AI systems themselves and the surrounding geopolitical situation. The coming years and decades thus present major challenges if we are to avoid large-scale risks from advanced AI systems, including:
- Loss of Control: AI disempowers humanity in pursuit of goals not aligned with our collective interests, which likely results in human extinction. Many experts have expressed concerns of this type. We see this as the default outcome of near-term ASI and refer readers to previous work on the topic: Managing extreme AI risks amid rapid progress, Without specific countermeasures, The Alignment Problem from a Deep Learning Perspective, Four Background Claims, Without fundamental advances.
- Misuse: Malicious or incautious actors use AI, deliberately or accidentally, leading to catastrophic harm. This may include biological weapons or other weapons of mass destruction.
- War: AI-related conflict between great powers causes catastrophic harm.
- Authoritarianism/Lock-in: The world locks in values or conditions that are harmful, such as a stable, global authoritarian regime.
This report provides an extensive collection of research questions intended to assist the US National Security community and the AI governance research ecosystem in preventing these catastrophic outcomes.
The presented research agenda is organized by four high-level scenarios for the trajectory of advanced AI development in the coming years: a coordinated global Halt on dangerous AI development (Off Switch and Halt), a US National Project leading to US global dominance (US National Project), continued private-sector development with limited government intervention (Light-Touch), and a world where nations maintain AI capabilities at safe levels through mutual threats of interference (Threat of Sabotage). We explore questions about the stability and viability of the governance strategy that underlies each scenario: What preconditions would make each scenario viable? What are the main difficulties of the scenario? How can these difficulties be reduced, including by transitioning to other strategies? What is a successful end-state for the scenario?
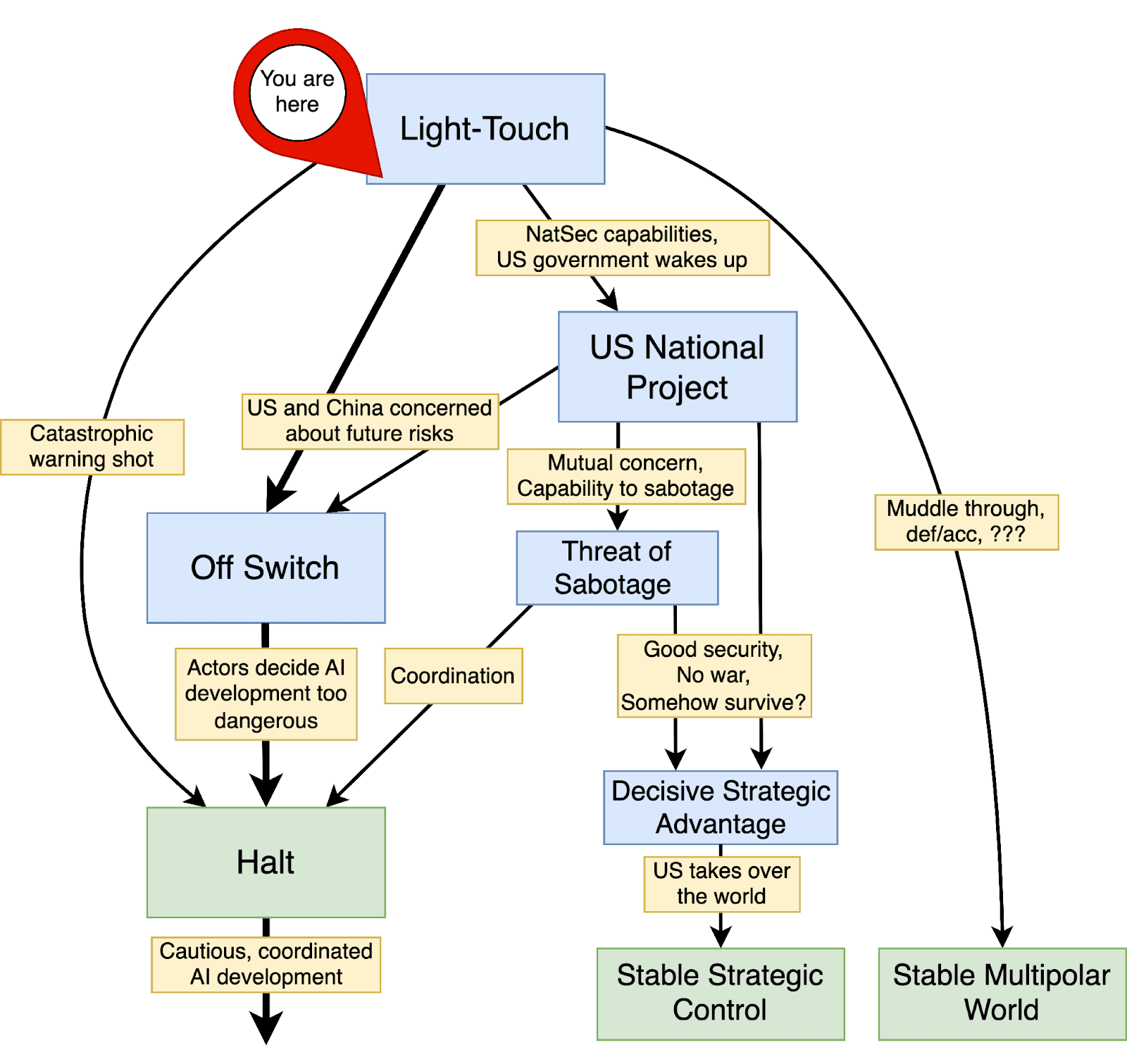
Off Switch and Halt
The first scenario we describe involves the world coordinating to develop the ability to monitor and restrict dangerous AI activities. Eventually, this may lead to a Halt: a global moratorium on the development and deployment of frontier AI systems until the field achieves justified confidence that progress can resume without catastrophic risk. Achieving the required level of understanding and assurance could be extraordinarily difficult, potentially requiring decades of dedicated research.
While consensus may currently be lacking about the need for such a Halt, it should be uncontroversial that humanity should be able to stop AI development in a coordinated fashion if or when it decides to do so. We refer to the technical, legal, and institutional infrastructure needed to Halt on demand as an Off Switch for AI.
We are focused on an Off Switch because we believe an eventual Halt is the best way to reduce Loss of Control risk from misaligned advanced AI systems. Therefore, we would like humanity to build the capacity for a Halt in advance. Even for those skeptical about alignment concerns, there are many reasons Off Switch capabilities would be valuable. These Off Switch capabilities—the ability to monitor, evaluate, and, if necessary, enforce restrictions on frontier AI development—would also address a broader set of national security concerns. They would assist with reducing risks from terrorism, geopolitical destabilization, and other societal disruption. As we believe a Halt is the most credible path to avoiding human extinction, the full research agenda focuses primarily on the Off Switch and Halt scenario.
The research questions in this scenario primarily concern the design of an Off Switch, and the key details to enforcing a Halt. For example:
- How do we create common understanding about AI risks and get buy-in from different actors to build the Off Switch?
- What features are needed for an effective Off Switch, and how can the world implement them?
- What are the trends in compute requirements for frontier AI systems?
- How can governments use controls on specialized chips to institute a long-term moratorium on dangerous AI?
- What is a suitable emergency response plan, for both AI projects and governments? How should actors respond to an AI emergency, including both mitigating immediate harm and learning the right lessons?
- What compute needs to be monitored after a Halt is initiated?
- How can governments monitor compute they know about, especially to ensure it isn’t being used to violate a Halt?
- Other than compute and security, what levers exist to control AI development and deployment?
US National Project
The second scenario is the US National Project, in which the US government races to develop advanced AI systems and establish unilateral control over global AI development. This scenario is based on stories discussed previously by Leopold Aschenbrenner and Anthropic CEO Dario Amodei. A successful US National Project requires navigating numerous difficult challenges:
- Maintaining a lead over other countries
- Avoiding the proliferation of advanced AI capabilities to terrorists
- Avoiding war with other countries
- Developing advanced AI capabilities despite potential hardware or software limits
- Avoiding the development of misaligned AI systems that lead to Loss of Control.
- Converting its AI capabilities advantage into a decisive advantage over other actors.
- Avoiding governance failure such as authoritarian power grabs.
Some of these challenges look very difficult, such that pursuing the project would be unacceptably dangerous. We encourage other approaches, namely coordinating a global Off Switch and halting dangerous AI development.
The research questions in this section examine how to prepare for and execute on the project, along with approaches for pivoting away from a National Project and into safer strategies. For example:
- How can the US lead in AI capabilities be measured?
- How could a centralized US National Project bring in other AI development projects (domestic and international)?
- What ready-to-go research should the US National Project prioritize using AIs for, when AIs are capable of automating AI safety research?
- What is a safety plan that would allow an AI project to either successfully build aligned advanced AI, or safely notice that its development strategy is too dangerous?
- What mechanisms are available to reduce racing between nations?
- How might the US National Project achieve a decisive strategic advantage using advanced AI?
- How could the US National Project recognize that its strategy is too dangerous?
Light-Touch
Light-Touch is similar to the current world, where the government takes a light-touch approach to regulating AI companies. We have not seen a credible story for how this situation is stable in the long run. In particular, we expect governments to become more involved in AI development as AIs become strategically important, both militarily and economically. Additionally, the default trajectory will likely involve the open release of highly capable AI models. Such models would drastically increase large-scale risks from malicious actors, for instance, by assisting with biological weapon development. One approach discussed previously to remedy this situation is defensive acceleration: investing heavily in defense-oriented technologies in order to combat offensive use. We are pessimistic about such an approach because some emerging technologies—such as biological weapons—appear much easier to weaponize than to defend against. The Light-Touch approach also involves similar risks to those in the US National Project, such as misalignment and war. We think the Light-Touch scenario is extremely unsafe.
The research questions in this section are largely about light government interventions to improve the situation or transitioning into an Off Switch strategy or US National Project. For example:
- What light-touch interventions are available to coordinate domestic AI projects to reduce corporate race dynamics?
- What dangerous capabilities will the government care about solely controlling, and when might these be developed?
- How does development of national security technology by the private sector typically work? What are the most important lessons to take away from existing public-private partnerships for such technologies?
- What kinds of transparency should governments have into private AI development?
- How can AI developers implement strong security for AI model weights? How could the government promote this?
- How can AI developers implement strong security for algorithmic secrets? How could the government promote this?
Threat of Sabotage
AI progress could disrupt the balance of power between nations (e.g., enable a decisive military advantage), so countries might take substantial actions to interfere with advanced AI development. Threat of Sabotage, similar to Mutual Assured AI Malfunction (MAIM) described in Superintelligence Strategy, describes a strategic situation where AI development is slow because countries threaten to sabotage rivals’ AI progress. Actual sabotage may occur, via substantial actions to interfere with AI development, although merely the threat of sabotage could be sufficient to keep AI progress slow. The state of thinking about this scenario is nascent, and we are excited to see further analysis of its viability and implications.
One of our main concerns is that the situation only remains stable if there is a high degree of visibility into AI projects and potential for sabotage, but these are both complicated factors that are difficult to predict in advance. Visibility and potential for sabotage are both likely high in the current AI development regime, where frontier AI training requires many thousands of advanced chips, but this situation could change.
The research questions in this section focus on better understanding the viability of the scenario and transitioning into a more cooperative Off Switch scenario. For example:
- Will the security levels in AGI projects be at the required level to enable the Threat of Sabotage dynamic? Threat of Sabotage largely requires that security in the main AGI projects is strong enough to prevent proliferation to non-state actors, but weak enough to enable countries to see each other’s progress and sabotage each other.
- What are the key methods countries might use to sabotage each other’s AGI projects? How effective are these? Would these prompt further escalation?
- How long would it take an actor to accomplish various key AI activities given different starting capabilities? For example, how long would it take to domestically produce AI chips, build an AI data center, or reach a particular AI model capability level?
- What might enable a transition from a Threat of Sabotage regime to an international Off Switch-style agreement with verification? For example, mechanisms for credible non-aggression or benefit sharing.
Understanding the World
There are some research projects that are generally useful for understanding the strategic situation and gaining situational awareness. We include some research projects in this section because they are broadly useful across many AI development trajectories. For example:
- How viable is compute governance?
- Understanding and forecasting model capabilities
- What are the trends in the cost of AI inference?
- What are the implications of the inference scaling regime?
- What is the state of AI hardware and the computing stock?
- What high-level plans and strategies for AI governance seem promising?
Outlook
Humanity is on track to soon develop AI systems smarter than the smartest humans; this might happen in the 2020s or 2030s. On both the current trajectory and some of the most likely variations (such as a US National Project), there is an unacceptably large risk of catastrophic harm. Risks include terrorism, world war, and risks from AI systems themselves (i.e., loss of control due to AI misalignment).
Humanity should take a different path. We should build the technical, legal, and institutional infrastructure needed to halt AI development if and when there is political will to do so. This Halt would provide the conditions for a more mature AI field to eventually develop this technology in a cautious, safe, and coordinated manner.
We hope this agenda can serve as a guide to others working on reducing large-scale AI risks. There is far too much work for us to do alone. We will make progress on only a small subset of these questions, and we encourage other researchers to work on these questions as well.
If you’re interested in collaborating with, joining, or even leading our work on these critical problems, please contact us.
| Scenario | Pros | Cons | Loss of Control | Misuse | War | Bad Lock-in |
| Off Switch and Halt |
Careful AI development; International legitimacy; Slow societal disruption |
Difficult to implement; Not a complete strategy; Slow AI benefits |
Low | Low | Low | Mid |
| US National Project |
Centralized ability to implement safeguards; Limited proliferation |
Arms race; Breaking international norms |
High | Low | High | High |
| Light-Touch |
Fast economic benefit; Less international provocation; Easy to implement (default) |
Corporate racing; Proliferation; Limited controls available; Untenable |
High | High | Mid | Mid |
| Threat of Sabotage |
Slower AI development; Limited cooperation needed |
Ambiguous stability; Escalation |
Mid | Low | High | Mid |
A table of the main pros and cons of the scenarios and how much of each core risk they involve. Ratings are based on our analysis of the scenarios. Color coding reflects the risk level.