
Update 2017-12-27: We’ve blown past our 3rd and final target, and reached the matching cap of $300,000 for the $2 million Matching Challenge! Thanks so much to everyone who supported us!
All donations made before 23:59 PST on Dec 31st will continue to be counted towards our fundraiser total. The fundraiser total includes projected matching funds from the Challenge.
MIRI’s 2017 fundraiser is live through the end of December! Our progress so far (updated live):
$2,504,625 raised in total!
358 donors contributed
MIRI is a research nonprofit based in Berkeley, California with a mission of ensuring that smarter-than-human AI technology has a positive impact on the world. You can learn more about our work at “Why AI Safety?” or via MIRI Executive Director Nate Soares’ Google talk on AI alignment.
In 2015, we discussed our interest in potentially branching out to explore multiple research programs simultaneously once we could support a larger team. Following recent changes to our overall picture of the strategic landscape, we’re now moving ahead on that goal and starting to explore new research directions while also continuing to push on our agent foundations agenda. For more on our new views, see “There’s No Fire Alarm for Artificial General Intelligence” and our 2017 strategic update. We plan to expand on our relevant strategic thinking more in the coming weeks.
Our expanded research focus means that our research team can potentially grow big, and grow fast. Our current goal is to hire around ten new research staff over the next two years, mostly software engineers. If we succeed, our point estimate is that our 2018 budget will be $2.8M and our 2019 budget will be $3.5M, up from roughly $1.9M in 2017. ((Note that this $1.9M is significantly below the $2.1–2.5M we predicted for the year in April. Personnel costs are MIRI’s most significant expense, and higher research staff turnover in 2017 meant that we had fewer net additions to the team this year than we’d budgeted for. We went under budget by a relatively small margin in 2016, spending $1.73M versus a predicted $1.83M.
Our 2018–2019 budget estimates are highly uncertain, with most of the uncertainty coming from substantial uncertainty about how quickly we’ll be able to take on new research staff.))
We’ve set our fundraiser targets by estimating how quickly we could grow while maintaining a 1.5-year runway, on the simplifying assumption that about 1/3 of the donations we receive between now and the beginning of 2019 will come during our current fundraiser. ((This is roughly in line with our experience in previous years, when excluding expected grants and large surprise one-time donations. We’ve accounted for the former in our targets but not the latter, since we think it unwise to bank on unpredictable windfalls.
Note that in previous years, we’ve set targets based on maintaining a 1-year runway. Given the increase in our size, I now think that a 1.5-year runway is more appropriate.))
Hitting Target 1 ($625k) then lets us act on our growth plans in 2018 (but not in 2019); Target 2 ($850k) lets us act on our full two-year growth plan; and in the case where our hiring goes better than expected, Target 3 ($1.25M) would allow us to add new members to our team about twice as quickly, or pay higher salaries for new research staff as needed.
We discuss more details below, both in terms of our current organizational activities and how we see our work fitting into the larger strategy space.
What’s new at MIRI | Fundraising goals | Strategic background
What’s new at MIRI
New developments this year have included:
- The release of Eliezer Yudkowsky’s Inadequate Equilibria: Where and How Civilizations Get Stuck, a book on systemic failure, outperformance, and epistemology.
- New introductory material on decision theory: “Functional Decision Theory,” “Cheating Death in Damascus,” and “Decisions Are For Making Bad Outcomes Inconsistent.”
- Extremely generous new support for our research in the form of a one-time $1.01 million donation from a cryptocurrency investor and a three-year $3.75 million grant from the Open Philanthropy Project. ((Including the $1.01 million donation and the first $1.25 million from the Open Philanthropy Project, we have so far raised around $3.16 million this year, overshooting the $3 million goal we set earlier this year!))
Thanks in part to this major support, we’re currently in a position to scale up the research team quickly if we can find suitable hires. We intend to explore a variety of new research avenues going forward, including making a stronger push to experiment and explore some ideas in implementation. ((We emphasize that, as always, “experiment” means “most things tried don’t work.” We’d like to avoid setting expectations of immediate success for this exploratory push.)) This means that we’re currently interested in hiring exceptional software engineers, particularly ones with machine learning experience.
The two primary things we’re looking for in software engineers are programming ability and value alignment. Since we’re a nonprofit, it’s also worth noting explicitly that we’re generally happy to pay excellent research team applicants with the relevant skills whatever salary they would need to work at MIRI. If you think you’d like to work with us, apply here!
In that vein, I’m pleased to announce that we’ve made our first round of hires for our engineer positions, including:
Jesse Liptrap, who previously worked on the Knowledge Graph at Google for four years, and as a bioinformatician at UC Berkeley. Jesse holds a PhD in mathematics from UC Santa Barbara, where he studied category-theoretic underpinnings of topological quantum computing.
Nick Tarleton, former lead architect at the search startup Quixey. He previously studied computer science and decision science at Carnegie Mellon University, and Nick worked with us at the first iteration of our summer fellows program, studying consequences of proposed AI goal systems.
On the whole, our initial hiring efforts have gone quite well, and I’ve been very impressed with the high caliber of our hires and of our pool of candidates.
On the research side, our recent work has focused heavily on open problems in decision theory, and on other questions related to naturalized agency. Scott Garrabrant divides our recent work on the agent foundations agenda into four categories, tackling different AI alignment subproblems:
- As Rob noted in April, “a common thread in our recent work is that we’re using probability and topological fixed points in settings where we used to use provability. This means working with (and improving) logical inductors and reflective oracles.” Examples of applications of logical induction to decision theory include logical inductor evidential decision theory (“Prediction Based Robust Cooperation,” “Two Major Obstacles for Logical Inductor Decision Theory“) and asymptotic decision theory (“An Approach to Logically Updateless Decisions,” “Where Does ADT Go Wrong?”).
- Unpacking the notion of updatelessness into pieces that we can better understand, e.g., in “Conditioning on Conditionals,” “Logical Updatelessness as a Robust Delegation Problem,” “The Happy Dance Problem.”
- The relationship between decision theories that rely on Bayesian conditionalization on the one hand (e.g., evidential decision theory and Wei Dai’s updateless decision theory), and ones that rely on counterfactuals on the other (e.g., causal decision theory, timeless decision theory, and the version of functional decision theory discussed in Yudkowsky and Soares (2017)): “Smoking Lesion Steelman,” “Comparing LICDT and LIEDT.”
- Lines of research relating to correlated equilibria, such as “A Correlated Analogue of Reflective Oracles” and “Smoking Lesion Steelman II.”
- The Converse Lawvere Problem (1, 2, 3): “Does there exist a topological space X (in some convenient category of topological spaces) such that there exists a continuous surjection from X to the space [0,1]X (of continuous functions from X to [0,1])?”
- Multi-agent coordination problems, often using the “Cooperative Oracles” framework.
- Kakutani’s fixed-point theorem and reflective oracles: “Hyperreal Brouwer.”
- Transparency and merging of opinions in logical inductors.
- Ontology merging, a possible approach to reasoning about ontological crises and transparency.
- Attempting to devise a variant of logical induction that is “Bayesian” in the sense that its belief states can be readily understood as conditionalized prior probability distributions.
- Goodhart’s Curse, “the combination of the Optimizer’s Curse and Goodhart’s Law” stating that “a powerful agent neutrally optimizing a proxy measure U that we hoped to align with true values V, will implicitly seek out upward divergences of U from V”: “The Three Levels of Goodhart’s Curse.”
- Corrigibility: “Corrigibility Thoughts,” “All the Indifference Designs.”
- Value learning and inverse reinforcement learning: “Incorrigibility in the CIRL Framework,” “Reward Learning Summary.”
- The reward hacking problem: “Stable Pointers to Value: An Agent Embedded In Its Own Utility Function.”
Additionally, we ran several research workshops, including one focused on Paul Christiano’s research agenda.
Fundraising goals
To a first approximation, we view our ability to make productive use of additional dollars in the near future as linear in research personnel additions. We don’t expect to run out of additional top-priority work we can assign to highly motivated and skilled researchers and engineers. This represents an important shift from our past budget and team size goals. ((Our previous goal was to slowly ramp up to the $3–4 million level and then hold steady with around 13–17 research staff. We now expect to be able to reach (and surpass) that level much more quickly.))
Growing our team as much as we hope to is by no means an easy hiring problem, but it’s made significantly easier by the fact that we’re now looking for top software engineers who can help implement experiments we want to run, and not just productive pure researchers who can work with a high degree of independence. (In whom we are, of course, still very interested!) We therefore think we can expand relatively quickly over the next two years (productively!), funds allowing.
In our mainline growth scenario, our reserves plus next year’s $1.25M installment of the Open Philanthropy Project’s 3-year grant would leave us with around 9 months of runway going into 2019. However, we have substantial uncertainty about exactly how quickly we’ll be able to hire additional researchers and engineers, and therefore about our 2018–2019 budgets.
Our 2018 budget breakdown in the mainline success case looks roughly like this:
2018 Budget Estimate (Mainline Growth)
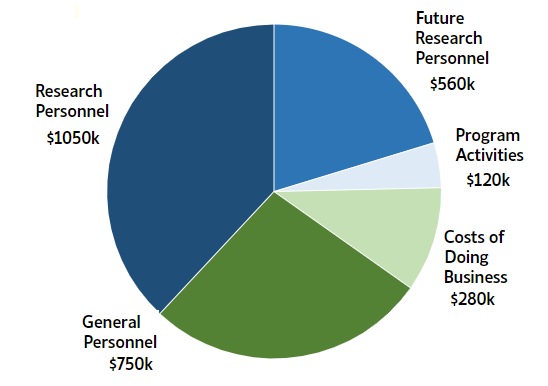
To determine our fundraising targets this year, we estimated the support levels (above the Open Philanthropy Project’s support) that would make us reasonably confident that we can maintain a 1.5-year runway going into 2019 in different growth scenarios, assuming that our 2017 fundraiser looks similar to next year’s fundraiser and that our off-fundraiser donor support looks similar to our on-fundraiser support:
Basic target — $625,000. At this funding level, we’ll be in a good position to pursue our mainline hiring goal in 2018, although we will likely need to halt or slow our growth in 2019.
Mainline-growth target — $850,000. At this level, we’ll be on track to fully fund our planned expansion over the next few years, allowing us to roughly double the number of research staff over the course of 2018 and 2019.
Rapid-growth target — $1,250,000. At this funding level, we will be on track to maintain a 1.5-year runway even if our hiring proceeds a fair amount faster than our mainline prediction. We’ll also have greater freedom to pay higher salaries to top-tier candidates as needed.
Beyond these growth targets: if we saw an order-of-magnitude increase in MIRI’s funding in the near future, we have several ways we believe we can significantly accelerate our recruitment efforts to grow the team faster. These include competitively paid trial periods and increased hiring outreach across venues and communities where we expect to find high-caliber candidates. Funding increases beyond the point where we could usefully use the money to hire faster would likely cause us to spin off new initiatives to address the problem of AI x-risk from other angles; we wouldn’t expect them to go to MIRI’s current programs.
On the whole, we’re in a very good position to continue expanding, and we’re enormously grateful for the generous support we’ve already received this year. Relative to our present size, MIRI’s reserves are much more solid than they have been in the past, putting us in a strong position going into 2018.
Given our longer runway, this may be a better year than usual for long-time MIRI supporters to consider supporting other projects that have been waiting in the wings. That said, we don’t personally know of marginal places to put additional dollars that we currently view as higher-value than MIRI, and we do expect our fundraiser performance to affect our growth over the next two years, particularly if we succeed in growing the MIRI team as fast as we’re hoping to.
Strategic background
Taking a step back from our immediate organizational plans: how does MIRI see the work we’re doing as tying into positive long-term, large-scale outcomes?
A lot of our thinking on these issues hasn’t yet been written up in any detail, and many of the issues involved are topics of active discussion among people working on existential risk from AGI. In very broad terms, however, our approach to global risk mitigation is to think in terms of desired outcomes, and to ask: “What is the likeliest way that the outcome in question might occur?” We then repeat this process until we backchain to interventions that actors can take today.
Ignoring a large number of subtleties, our view of the world’s strategic situation currently breaks down as follows:
In order to avoid making critical decisions in haste and locking in flawed conclusions, humanity needs:
Given the difficulty of the task, we expect a successful stable period to require:
To end the acute risk period, we expect it to be necessary for actors to make use of:
We believe that the likeliest way to achieve a technology in this category sufficiently soon is through:
Added: “Minimal aligned AGI” means “aligned AGI that has the minimal necessary capabilities”; be sure not to misread it as “minimally aligned AGI”. Rob Bensinger adds: “The MIRI view isn’t ‘rather than making alignment your top priority and working really hard to over-engineer your system for safety, try to build a system with the bare minimum of capabilities’. It’s: ‘in addition to making alignment your top priority and working really hard to over-engineer your system for safety, also build the system to have the bare minimum of capabilities’.”
If an aligned system of this kind were developed, we would expect two factors to be responsible:
On our current understanding of the alignment problem, developers need to be able to give a reasonable account of how all of the AGI-grade computation in their system is being allocated, similar to how secure software systems are built to allow security professionals to give a simple accounting of why the system has no unforeseen vulnerabilities. See “Security Mindset and Ordinary Paranoia” for more details.
Developers must be able to explicitly state and check all of the basic assumptions required for their account of the system’s alignment and effectiveness to hold. Additionally, they need to design and modify AGI systems only in ways that preserve understandability — that is, only allow system modifications that preserve developers’ ability to generate full accounts of what cognitive problems any given slice of the system is solving, and why the interaction of all of the system’s parts is both safe and effective.
Our view is that this kind of system understandability will in turn require:
We expect this to be a critical step, as we do not expect most approaches to AGI to be alignable after the fact without long, multi-year delays.
We plan to say more in the future about the criteria for operationally adequate projects in 7a. We do not believe that any project meeting all of these conditions currently exists, though we see various ways that projects could reach this threshold.
The above breakdown only discusses what we view as the “mainline” success scenario. ((There are other paths to good outcomes that we view as lower-probability, but still sufficiently high-probability that the global community should allocate marginal resources to their pursuit.)) If we condition on good long-run outcomes, the most plausible explanation we can come up with cites an operationally adequate AI-empowered project ending the acute risk period, and appeals to the fact that those future AGI developers maintained a strong understanding of their system’s problem-solving work over the course of development, made use of advance knowledge about which AGI approaches conduce to that kind of understanding, and filtered on those approaches.
For that reason, MIRI does research to intervene on 8 from various angles, such as by examining holes and anomalies in the field’s current understanding of real-world reasoning and decision-making. We hope to thereby reduce our own confusion about alignment-conducive AGI approaches and ultimately help make it feasible for developers to construct adequate “safety-stories” in an alignment setting. As we improve our understanding of the alignment problem, our aim is to share new insights and techniques with leading or up-and-coming developer groups, who we’re generally on good terms with.
A number of the points above require further explanation and motivation, and we’ll be providing more details on our view of the strategic landscape in the near future.
Further questions are always welcome at contact@intelligence.org, regarding our current organizational activities and plans as well as the long-term role we hope to play in giving AGI developers an easier and clearer shot at making the first AGI systems robust and safe. For more details on our fundraiser, including corporate matching, see our Donate page.